Overview [1]
kubernetes集群中的调度程序 kube-scheduler 会 watch 未分配节点的新创建的Pod,并未该Pod找到可运行的最佳(特定)节点。那么这些动作或者说这些原理是怎么实现的呢,让我们往下剖析下。
对于新创建的 pod 或其他未调度的 pod来讲,kube-scheduler 选择一个最佳节点供它们运行。但是,Pod 中的每个容器对资源的要求都不同,每个 Pod 也有不同的要求。因此,需要根据具体的调度要求对现有节点进行过滤。
在Kubernetes集群中,满足 Pod 调度要求的节点称为可行节点 ( feasible nodes FN) 。如果没有合适的节点,则 pod 将保持未调度状态,直到调度程序能够放置它。也就是说,当我们创建Pod时,如果长期处于 Pending 状态,这个时候应该看你的集群调度器是否因为某些问题没有合适的节点了
调度器为 Pod 找到 FN 后,然后运行一组函数对 FN 进行评分,并在 FN 中找到得分最高的节点来运行 Pod。
调度策略在决策时需要考虑的因素包括个人和集体资源需求、硬件/软件/策略约束 (constraints)、亲和性 (affinity) 和反亲和性( anti-affinity )规范、数据局部性、工作负载间干扰等。
如何为pod选择节点?
kube-scheduler 为pod选择节点会分位两部:
- 过滤 (
Filtering) - 打分 (
Scoring)
过滤也被称为预选 (Predicates),该步骤会找到可调度的节点集,然后通过是否满足特定资源的请求,例如通过 PodFitsResources 过滤器检查候选节点是否有足够的资源来满足 Pod 资源的请求。这个步骤完成后会得到一个包含合适的节点的列表(通常为多个),如果列表为空,则Pod不可调度。
打分也被称为优选(Priorities),在该步骤中,会对上一个步骤的输出进行打分,Scheduer 通过打分的规则为每个通过 Filtering 步骤的节点计算出一个分数。
完成上述两个步骤之后,kube-scheduler 会将Pod分配给分数最高的 Node,如果存在多个相同分数的节点,会随机选择一个。
kubernetes的调度策略
Kubernetes 1.21之前版本可以在代码 kubernetes\pkg\scheduler\algorithmprovider\registry.go 中看到对应的注册模式,在1.22 scheduler 更换了其路径,对于registry文件更换到了kubernetes\pkg\scheduler\framework\plugins\registry.go ;对于kubernetes官方说法为,调度策略是用于“预选” (Predicates )或 过滤(filtering ) 和 用于 优选(Priorities)或 评分 (scoring)的
注:kubernetes官方没有找到预选和优选的概念,而Predicates和filtering 是处于预选阶段的动词,而Priorities和scoring是优选阶段的动词。后面用PF和PS代替这个两个词。
为Pod预选节点 [2]
上面也提到了,filtering 的目的是为了排除(过滤)掉不满足 Pod 要求的节点。例如,某个节点上的闲置资源小于 Pod 所需资源,则该节点不会被考虑在内,即被过滤掉。在 “Predicates” 阶段实现的 filtering 策略,包括:
NoDiskConflict:评估是否有合适Pod请求的卷NoVolumeZoneConflict:在给定zone限制情况下,评估Pod请求所需的卷在Node上是否可用PodFitsResources:检查空闲资源(CPU、内存)是否满足Pod请求PodFitsHostPorts:检查Pod所需端口在Node上是否被占用HostName: 过滤除去,PodSpec中NodeName字段中指定的Node之外的所有Node。MatchNodeSelector:检查Node的 label 是否与 Pod 配置中nodeSelector字段中指定的 label 匹配,并且从 Kubernetes v1.2 开始, 如果存在nodeAffinity也会匹配。CheckNodeMemoryPressure:检查是否可以在已出现内存压力情况节点上调度 Pod。CheckNodeDiskPressure:检查是否可以在报告磁盘压力情况的节点上调度 Pod
具体对应得策略可以在 kubernetes\pkg\scheduler\framework\plugins\registry.go 看到
对预选节点打分 [2]
通过上面步骤过滤过得列表则是适合托管的Pod,这个结果通常来说是一个列表,如何选择最优Node进行调度,则是接下来打分的步骤步骤。
例如:Kubernetes对剩余节点进行优先级排序,优先级由一组函数计算;优先级函数将为剩余节点给出从0~10 的分数,10 表示最优,0 表示最差。每个优先级函数由一个正数加权组成,每个Node的得分是通过将所有加权得分相加来计算的。设有两个优先级函数,priorityFunc1 和 priorityFunc2 加上权重因子 weight1 和weight2,那么这个Node的最终得分为:$finalScore = (w1 \times priorityFunc1) + (w2 \times priorityFunc2)$。计算完分数后,选择最高分数的Node做为Pod的宿主机,存在多个相同分数Node情况下会随机选择一个Node。
目前kubernetes提供了一些在打分 Scoring 阶段算法:
LeastRequestedPriority:Node的优先级基于Node的空闲部分$\frac{capacity\ -\ Node上所有存在的Pod\ -\ 正在调度的Pod请求}{capacity}$,通过计算具有最高分数的Node是FNBalancedResourceAllocation:该算法会将 Pod 放在一个Node上,使得在Pod 部署后 CPU 和内存的使用率为平衡的SelectorSpreadPriority:通过最小化资源方式,将属于同一种服务、控制器或同一Node上的Replica的 Pod的数量来分布Pod。如果节点上存在Zone,则会调整优先级,以便 pod可以分布在Zone之上。CalculateAntiAffinityPriority:根据label来分布,按照相同service上相同label值的pod进行分配ImageLocalityPriority:根据Node上镜像进行打分,Node上存在Pod请求所需的镜像优先级较高。
在代码中查看上述的代码
以 PodFitsHostPorts 算法为例,因为是Node类算法,在kubernetes\pkg\scheduler\framework\plugins\nodeports
调度框架 [3]
调度框架 (scheduling framework SF ) 是kubernetes为 scheduler设计的一个pluggable的架构。SF 将scheduler设计为 Plugin 式的 API,API将上一章中提到的一些列调度策略实现为 Plugin。
在 SF 中,定义了一些扩展点 (extension points EP ),而被实现为Plugin的调度程序将被注册在一个或多个 EP 中,换句话来说,在这些 EP 的执行过程中如果注册在多个 EP 中,将会在多个 EP 被调用。
每次调度都分为两个阶段,调度周期(Scheduling Cycel)与绑定周期(Binding Cycle)。
- SC 表示为,为Pod选择一个节点;SC 是串行运行的。
- BC 表示为,将 SC 决策结果应用于集群中;BC 可以同时运行。
调度周期与绑定周期结合一起,被称为调度上下文 (Scheduling Context),下图则是调度上下文的工作流
注:如果决策结果为Pod的调度结果无可用节点,或存在内部错误,则中止 SC 或 BC。Pod将重入队列重试
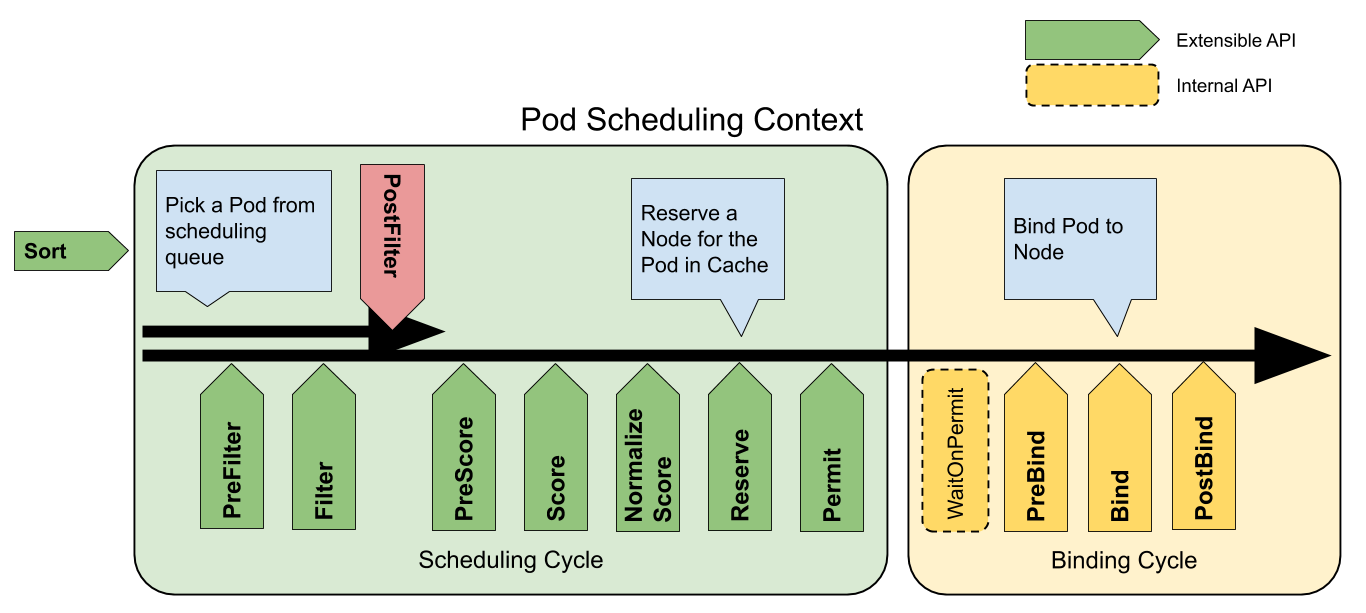
扩展点 [4]
扩展点(Extension points)是指在调度上下文中的每个可扩展API,通过图提现为[图1]。其中 Filter 相当于 Predicate 而 Scoring 相当于 Priority。
对于调度阶段会通过以下扩展点:
Sort:该插件提供了排序功能,用于对在调度队列中待处理 Pod 进行排序。一次只能启用一个队列排序。preFilter:该插件用于在过滤之前预处理或检查 Pod 或集群的相关信息。这里会终止调度filter:该插件相当于调度上下文中的Predicates,用于排除不能运行 Pod 的节点。Filter 会按配置的顺序进行调用。如果有一个filter将节点标记位不可用,则将 Pod 标记为不可调度(即不会向下执行)。postFilter:当没有为 pod 找到FN时,该插件会按照配置的顺序进行调用。如果任何postFilter插件将 Pod 标记为schedulable,则不会调用其余插件。即filter成功后不会进行这步骤preScore:可用于进行预Score工作(通知性的扩展点)。score:该插件为每个通过filter阶段的Node提供打分服务。然后Scheduler将选择具有最高加权分数总和的Node。reserve:因为绑定事件时异步发生的,该插件是为了避免Pod在绑定到节点前时,调度到新的Pod,使节点使用资源超过可用资源情况。如果后续阶段发生错误或失败,将触发UnReserve回滚(通知性扩展点)。这也是作为调度周期中最后一个状态,要么成功到postBind,要么失败触发UnReserve。permit:该插件可以阻止或延迟 Pod 的绑定,一般情况下这步骤会做三件事:appove:调度器继续绑定过程Deny:如果任何一个Premit拒绝了Pod与节点的绑定,那么将触发UnReserve,并重入队列Wait: 如果 Permit 插件返回Wait,该 Pod 将保留在内部WaitPod 列表中,直到被Appove。如果发生超时,wait变为deny,将Pod放回至调度队列中,并触发Unreserve回滚 。
preBind:该插件用于在 bind Pod 之前执行所需的前置工作。如,preBind可能会提供一个网络卷并将其挂载到目标节点上。如果在该步骤中的任意插件返回错误,则Pod 将被deny并放置到调度队列中。bind:在所有的preBind完成后,该插件将用于将Pod绑定到Node,并按顺序调用绑定该步骤的插件。如果有一个插件处理了这个事件,那么则忽略其余所有插件。postBind:该插件在绑定 Pod 后调用,可用于清理相关资源(通知性的扩展点)。multiPoint:这是一个仅配置字段,允许同时为所有适用的扩展点启用或禁用插件。
kube-scheduler工作流分析
对于 kube-scheduler 组件的分析,包含 kube-scheduler 启动流程,以及scheduler调度流程。这里会主要针对启动流程分析,后面算法及二次开发部分会切入调度分析。
对于我们部署时使用的 kube-scheduler 位于 cmd/kube-scheduler ,在 Alpha (1.16) 版本提供了调度框架的模式,到 Stable (1.19) ,从代码结构上是相似的;直到1.22后改变了代码风格。
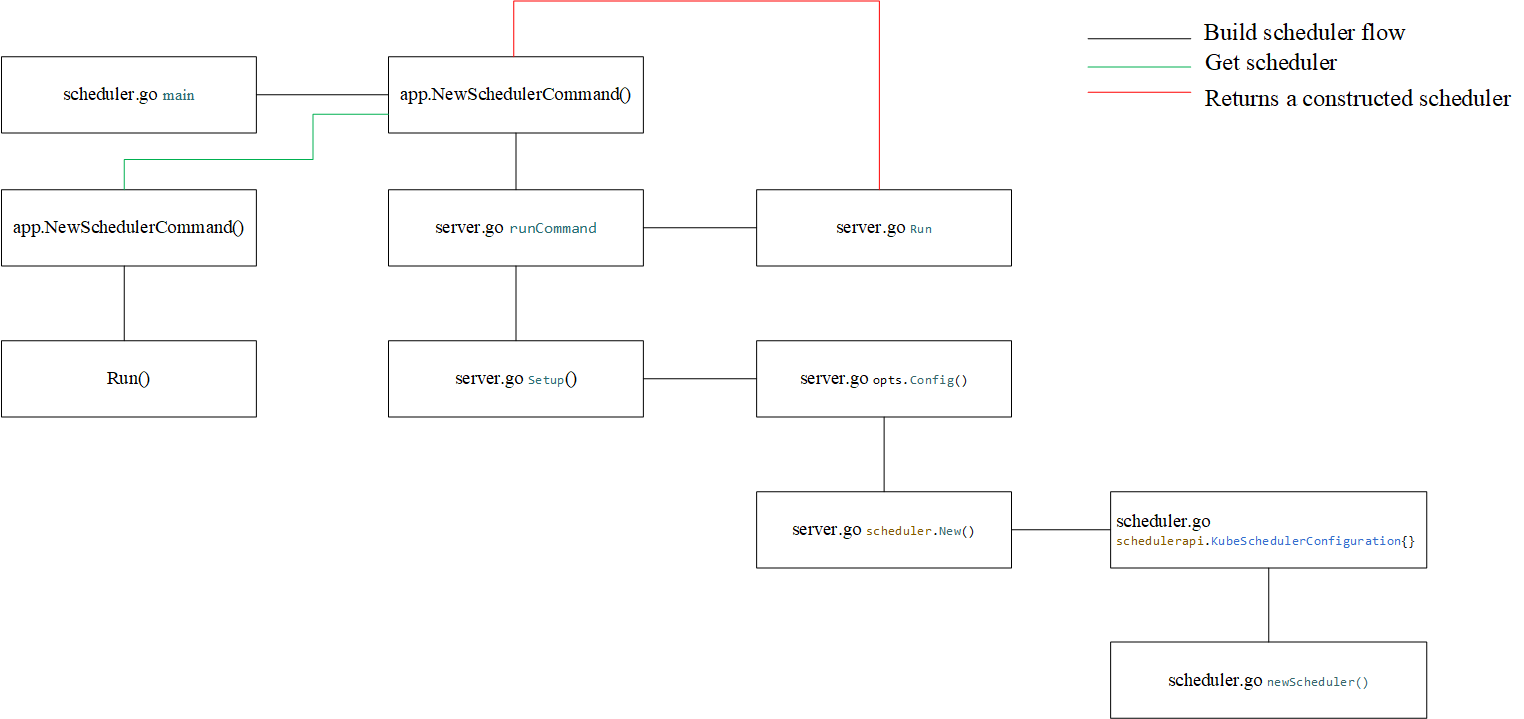
首先看到的是 kube-scheduler 的入口 cmd/kube-scheduler ,这里主要作为两部分,构建参数与启动server ,这里严格来讲 kube-scheduer 是作为一个server,而调度框架等部分是另外的。
| |
cli.Run 提供了cobra构成的命令行cli,日志将输出为标准输出
| |
可以看到最终是调用 command.Execute() 执行,这个是执行本身构建的命令,而真正被执行的则是上面的 app.NewSchedulerCommand() ,那么来看看这个是什么
app.NewSchedulerCommand() 构建了一个cobra.Commond对象, runCommand() 被封装在内,这个是作为启动scheduler的函数
| |
下面来看下 runCommand() 在启动 scheduler 时提供了什么功能。
在新版中已经没有 algorithmprovider 的概念,所以在 runCommand 中做的也就是仅仅启动这个 scheduler ,而 scheduler 作为kubernetes组件,也是会watch等操作,自然少不了informer。其次作为和 controller-manager 相同的工作特性,kube-scheduler 也是 基于Leader选举的。
| |
上面看到了 runCommend 是作为启动 scheduler 的工作,那么通过参数构建一个 scheduler 则是在 Setup 中完成的。
| |
上面了解到了 scheduler 是如何被构建出来的,下面就看看 构建时参数是如何传递进来的,而对象 option就是对应需要的配置结构,而 ApplyTo 则是将启动时传入的参数转化为构建 scheduler 所需的配置。
对于Deprecated flags可以参考官方对于kube-scheduler启动参数的说明 [5]
| |
Setup 后会new一个 schedueler , New 则是这个动作,在里面可以看出,会初始化一些informer与 Pod的list等操作。
| |
接下来会启动这个 scheduler, 在上面我们看到 NewSchedulerCommand 构建了一个cobra.Commond对象, runCommand() 最终会返回个 Run,而这个Run就是启动这个 sche 的。
下面这个 run 是 sche 的运行,他运行并watch资源,直到上下文完成。
| |
而调用这个 Run 的部分则是作为server的 kube-scheduler 中的 run
| |
而上面的 server.Run 会被 runCommand 也就是在 NewSchedulerCommand 时被返回,在 kube-scheduler 的入口文件中被执行。
| |
至此,整个 kube-scheduler 启动流就分析完了,这个的流程可以用下图表示
Reference
[1] kube scheduler
[2] Scheduler Algorithm in Kubernetes
[3] scheduling framework
[4] permit