本文发布于Cylon的收藏册,转载请著名原文链接~
1 Memcached介绍及常见同类软件对比
1.1 Memcached是什么?
Memcached是一个开源的、支持高性能、高并发的分布式缓存系统,由C语言编写,总共2000多行代码。从软件名称上看,前3个字符的单词Mem就是内存的意思,接下来的后面5个字符的单词Cache就是缓存的意思,最后一个字符d是daemon的意思,代表是服务端守护进程模式服务。
Memcached服务分为服务端和客户端两部分,其中,服务端软件的名字形如 Memcached-1.4.24.tat.gz,客户端软件的名字形如 Memcache-2.25.tar.gz
Memcached软件诞生于2003年,最初由LiveJournal的BradFitzpatrick开发完成。Memcached是整个项目的名称,而Memcached是服务器端的主程序名,因其协议简单,使用部署方便、且支持高并发而被互联网企业广泛使用,知道现在仍然被广泛应用。官方网址:http://memcached.org
1.2 Memcached的作用
传统场景,多数Web应用都将数据保存到关系型数据库中(例如MySQL),Web服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,关系型数据库的负担就会加重、响应缓慢、导致网站打开延迟等问题,影响用户体验。
这时就需要Memcached软件出马了。使用Memcached的主要目的是,通过在自身内存中缓存关系型数据库的查询结果,减少数据库自身被访问的次数,以提高动态web应用的速度、提高网站架构的并发能力和可扩展性。
Memcached服务的运行原理是通过在实现规划好的系统内存空间中临时缓存数据库的各类数据,以达到减少前端业务服务对数据库的直接高并发访问,从而达到提升大规模网站急群众动态服务的并发访问能力。
生产场景的Memcached服务一般被用来保存网站中经常被读取的对象或数据,就像我们的客户端浏览器也会把经常访问的网页缓存起来一样,通过内存缓存来存取对象或数据要比磁盘存取快很多,因为磁盘是机械的,因此,在当今的IT企业中,Memcached的应用范围很广泛
1.3 互联网常见内存服务软件
下表为互联网企业场景常见内存缓存服务软件相关对比信息:
| 软件 | 类型 | 主要作用 | 缓存的数据 |
|---|---|---|---|
| Memcached | 纯内存型 | 常用于缓存网站后端的各类数据,例如数据库中的数据 | 主要缓存用户重复请求的动态内容,blog的博文BBS的帖子等内容用户的Session会话信息 |
| Redis/Mongodb/memcachedb | 可持久化存储,即使用内存也会使用磁盘存储 | 1. 缓存后端数据库的查询数据 2.作为关系数据库的重要补充 |
1.作为缓存:主要缓存用户重复请求的动态内容:例如BLOG的博文、BBS的帖子等内容。2.作为数据库的有效补充:例如:好友关注、粉丝统计、业务统计等功能可以用持久化存储。 |
| Squid/Nginx | 内存或内存加磁盘缓存 | 主要用于缓存web前端的服务内容 | 主要用于静态数据缓存,例如:图片,附件(压缩包),js,css,html等,此部分功能大多数企业会选择专业的CDN公司如:蓝讯、网宿。 |
2 Memcached常见用途工作流程
Memcached是一种内存缓存软件,在工作中经常用来缓存数据库的查询数据,数据被缓存在事先预分配的Memcached管理的内存中,可以通过API或命令的方式存取内存中缓存的这些数据,Memcached服务内存中缓存的数据就像一张巨大的HASH表,每条数据都是以key-value对的形式存在。
2.1 网站读取Memcached数据时的工作流程
Memcached用来缓存查询到的数据库中的数据,逻辑上,当程序访问后端数据库获取数据时会先优先访问Memcached缓存,如果缓存中有数据就直接返回给客户端用户,如果没有数据(没有命中)程序再去读取后端的数据库的数据,读取到需要的数据后,把数据返回给客户端,同时还会把读取到的数据库缓存到Memcached内存中,这样客户端用户再请求相同数据就会直接读取Memcached缓存的数据,这样就大大减轻了后端数据库的压力,并提高了整个网站的响应速断,提升了用户体验。
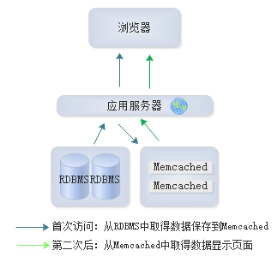
上图,使用Memcached缓存查询数据来减少数据库压力的具体工作流程如下:
-
web程序首先检查客户端请求的数据是否在Memcached缓存中存在,如果存在,直接把请求的数据返回给客户端,此时不在请求后端数据库。
-
如果请求的数据在Memcached缓存中不存在,则程序会请求数据库服务,把数据库中取到的数据返回给客户端,此时不再请求后端数据库。
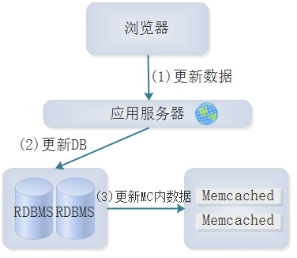
2.2 网站更新Memcached数据时工作流程
- 当程序更新或者删除数据时,会首先处理后端数据库中的数据。
- 程序处理后端数据库中的数据的同时,也会通知Memcached中的对应旧数据失效,从而保证Memcached中缓存的数据始终和数据库中的户数一直,这个数据一致性非常重要,也是大型网站分布式缓存集群的最头痛的问题所在。
- 如果是在高并发读写场合,除了要程序通知Memcached过期的缓存失效外,还可能会通过相关机制,例如在数据库上部署相关程序(例如:在数据库中设置触发器使用UDFs),实现当数据库有更新就会把数据更新到Memcached服务中,使得客户端在访问新数据前,预先把更新过的数据库数据复制到Memcached中缓存起来,这样可以减少第一次查询数据库带来的访问压力,提升Memcached中缓存的命中率,甚至sina门户还会把持久化存储redis做成MySQL数据库的从库,实现真正的主从复制。
3 Memcached在企业中的应用场景
3.1 作为数据库查询数据缓存
3.1.1 完整数据缓存
例如电商的商品分类功能不会经常变动,就可以实现放到Memcached里,然后再对外提供数据访问。这个过程被称之为“数据预热”。
此时秩序读取缓存无需读取数据库就能读到Memcached缓存里的所有商品分类数据了,所以数据库的访问压力就会大大降低了。
为什么商品分类数据可以实现放在缓存里呢?
因为,商品分类几乎都是由内部人员管理的,如果需要更新数据,更新数据库后,就可以把数据同时更新到Memcached里。
如果把商品分类数据做成静态化文件,然后通过在前段WEB缓存或者使用CDN加速效果更好。
3.1.2 热点数据缓存
热点数据缓存一般是用于由用户更新的商品,例如淘宝的卖家,当卖家新增商品后,网站程序就会把商品写入后端数据库,同时把这部分数据,放入Memcached内存中,下一次访问这个商品的请求就直接从Memcached内存中取走了。这种方法用来缓存网站热点的数据,即利用Memcached缓存经常被访问的数据。
特别提示:这个过程可以通过程序实现,也可以在数据库上安装软件进行设置,直接由数据库把内容更新到Memcached中,相当于Memcached是MySQL的丛库一样。
淘宝、京东、小米等电商双11秒杀抢购场景:
如果碰到电商双11秒杀高并发的业务场景,必须要实现预热各种缓存,包括前端的web缓存和后端的数据缓存。
先把数据放入内存预热,然后在逐步动态更新。先读取缓存,如果缓存里没有对应的数据,再去读取数据库,然后把读到的数据放入缓存。如果数据库里的数据更细,需要同时触发缓存更细,防止给用户过期的数据,当然对于百万级别并发还有很多其它的工作要做。
⚠ 提示:这个过程可以通过程序实现,也可以在数据库上安装相关软件进行设置,直接由数据库把内容更新到Memcached中,就相当于Memcached是MySQL的从库一样
如果碰到双十一、秒杀高并发的业务场景,必须要事先预热各种缓存,包括前段的Web缓存和后端的数据缓存。
也就是说事先把数据放入内存预热,然后逐步动态更新。此时,会先读取缓存,如果缓存里没有对应的数据,再去读取数据库,然后把读到的数据放入缓存。如果数据库里的数据更新,需要同时触发缓存更新,防止给用户过期的数据,当然对于百万级别并发还有很多其他的工作要做。
绝大多数的网站动态数据都是保存在数据库当中的,每次频繁地存取数据库,会导致数据库性能急剧下降,无法同时服务更多的用户(比如MySQL特别频繁的表锁就会存在此问题),那么,就可以让Memcached来分担数据库的压力。增加Memcached服务的好处除了可以分担数据库的压力以外,还包括无须改动整个网站架构,只需简单修改下程序逻辑,让程序先读取Memcached缓存查询数据即可。更新数据时也要更新Memcached缓存。
【分布式应用1】
Memcached支持分布式,我们在应用服务程序上改造,就可以更好的支持。例如:可以根据key适当进行有规律的封装,比如以用户位置的网站来说,每个用户都有UID。那么可以按照固定的ID来进行提取和存取,比如1开头的用户保存在第一台Memcached服务器上,以2开头的用户的数据保存在第二天Memcached服务器上,存取数据都先按照UID来进行的转换和存取。
【分布式应用2】
在应用服务器上通过程序及URL_HASH,抑制性哈希算法区访问Memcache服务,所有Memcached服务器的地址池可以简单的配在程序的配置文件里。
【分布式应用3】
门户网站如百度,会通过一个中间件代理负责请求后端的Cache服务。
【分布式应用4】
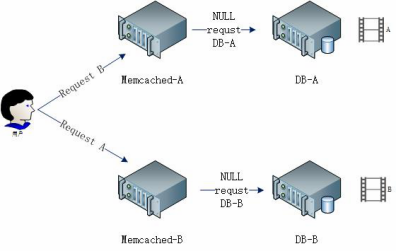
可以用常见的LVS haproxy做Cache的负载均衡,和普通应用服务相比,这里的重点是轮训算法,一般会选择url_hash,及consistent hash算法。
算法重要性图解
3.2 作为集群节点的session会话存储
即把客户端用户请求多个前端应用服务集群产生的session会话信息,统一存储到一个Memcached缓存中。由于session会话数据是存储在内存中的,所以速度很快。
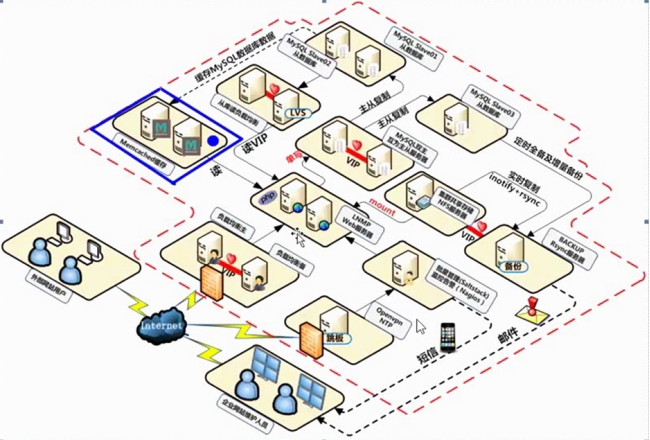
图3-2为Memcached服务在企业集群架构中常见的工作位置。
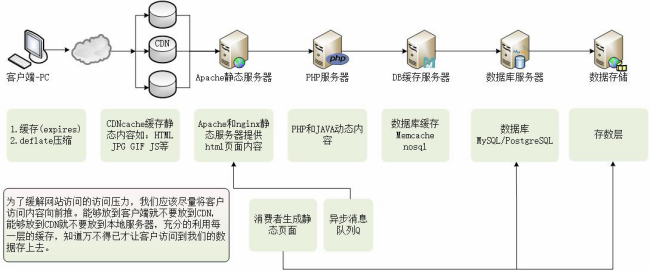
3.3 Memcached服务在企业集群架构中的位置
下图为Memcached服务在企业集群架构中常见的工作位置。
3.4 缓存雪崩效应
一般是由于某个节点生效,导致其他节点的缓存命中率下降,缓存中缺失的数据去数据可查询。短时间内造成数据库服务器崩溃。或,由于缓存周期性的输小,如:6小时失效一次,那么每6小时,将有一个请求"峰值",严重情况下会导致数据库宕机。
4 Memcached的特点与工作机制
4.1 Memcache的特征
Memcached作为高并发、高性能的缓存服务,具有如下特征:
4.1.1 协议简单
Memcached的协议实现简单,采用基于文本行的协议,能通过telnet/nc等命令直接操作Memcached服务读取数据。
4.1.2 支持epoll/kqueue异步I/O模型,使用libevent作为事件处理通知机制。
简单的说libevent是一套利用C开发的程序库,他将BSD系统的kqueue,Linux系统的epoll等事件处理功能封装成一个接口,确保即使服务器端的连接数量增加也能发挥很好的性能。Memcached就是利用这个libevent库进行异步事件处理。
4.1.3 key/value键值数据类型
被缓存的数据以key/value键形式存在的,例如:
zhangsan=>23 key=zhangsan value=23
通过zhangsan key可以获取到23
4.1.4 全内存缓存,效率高
Memcached管理内存的方式非常搞笑,即全部的数据都存放于Memcached服务实现分配好的内存中,无持久化存储的设计,和系统的物理内存一样,当重启系统或Memcached服务时,Memcached内存中的数据即会丢失。
如果希望重启后,数据依然能保存,那么就可以采用redis这样的持久性内存缓存系统的缓存数据。也可以在存放数据时,对存储的数据设置过期时间,这样过期后数据就自动被清除,Memcached服务本身不会监控数据过期,而是在访问的时候查看key的时间戳判断是否过期。
4.1.5 可支持分布式集群
Memcached没有像MySQL那样的主从复制方式,分布式Memcached集群的不同服务器之间是互不通讯的,每一个节点都独立存取数据,并且数据内容也不一样。通过对Web应用端的程序设计或者通过支持hash算法的负载均衡软件,可以让Memcached支持大规模海量分布式缓存集群应用。
4.2 Memcached工作原理与机制
4.2.1 Memcached工作原理
Memcached是一套类似C/S模式的架构软件,在服务器端启动Memcached服务守护进程,可以指定监听本地的IP地址、端口号、并发访问连接数,以及分配了多少内存来处理客户端请求。
4.2.2 Socket时间处理机制
Memcached软件是由C语言来实现的,全部代码仅有2000多行,采用的是异步epoll/kqueue非阻塞I/O网络模型,其实现方式是基于异步的libevent时间单进程、单线程模式。使用libevent作为事件通知机制,应用程序端通过指定服务器的IP地址及端口,就可以连接Memcached服务进程通讯。
4.2.3 数据存储机制
需要被缓存的数据以key/value键值对的形式保存在服务器端预分配的内存区中,每个被缓存的数据都有唯一的标识key,操作Memcached中的数据就是通过这个唯一标识的key进行的。缓存到Memcached中的数据仅放置在Memcached服务预分配的内存中,而非存储在Memcached服务器所在的磁盘上,因此存取速度非常快。
由于Memcached服务自身没有对缓存的数据进行持久化存储的设计,因此,在服务端的Memcached服务进程重启之后,存储在内存中的这些数据都会丢失。且当内存中缓存的数据容量达到启动时设定的内存值时,也会自动使用LRU算法删除过期的数据。
开发Memcached的初衷仅是通过内存缓存提示访问效率,并没有过多考虑数据的永久存储问题。因此,如果使用Memcached作为缓存数据服务,要考虑数据丢失后带来的问题,例如:是否可以重新生成数据,还有,在高并发场合下缓存宕机或重启会不会导致大量请求直接到数据库,导致数据库无法承受,最终导致网站架构雪崩等。
4.2.4 内存管理机制
- Memcached采用了如下机制:
- 采用slab内存分配机制。
- 采用LRU对象清除机制。
- 采用hash机制快速检索item。
4.2.5 多线程处理机制
- 多线程处理时采用的是pthread(POSIX)线程模式。
- 若要激活多线程,可在编译时指定:
./configure --enable-threads。 - 锁机制不够完善。
- 负载过重时,可以开启多线程(-t线程数为CPU核数)。
4.3 Memcached预热理念及集群节点的正确重启方法
4.3.1 Memcached预热理念
当需要大面积重启Memcached时,首先要在前端控制网站入口的访问流量,然后重启Memcached集群并进行数据预热,所有数据都预热完毕之后,在逐步开放前端网站入口的流量。
为了满足Memcached服务可以持久化存储的需求,在较早时期,新浪网基于Memcached服务开发了一款NoSQL软件,名字为MemcacheDB,实现了在缓存的基础上增加了之久存储的特性,不过目前逐步被更优秀的redis mongodb取代了。
4.3.2 如何正确开启网站集群服务器
如果由于机房断电或者搬迁服务器集群到新机房,那么启动集群服务器时,一定要从网站集群的后端**==依次往前端开启==**,特别是开启Memcached缓存服务器时要提前预热。
5 Memcached内存管理
5.1 Memcached内存管理机制深入剖析
5.1.1 Malloc内存管理机制
在讲解Memcached内存管理机制前,先来了解malloc。
malloc的全称是memory allocation,中文名称动态内存分配,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态分配内存。
早期的Memcached内存管理是通过malloc分配的内存实现的,使用完后通过free来回收内存。这种方式容易产生内存碎片并降低操作系统对内存的管理效率。因此,也会加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比Memcached进程本身还慢,为了解决上述问题,Slab Allocator内存分配机制就诞生了。
5.1.2 Slab内存管理机制
现在的Memcached是利用Slab Allocation机制来分配和管理内存的,过程如下。
- 提前将大内存分配大小为1MB的若干个slab,然后针对每个slab在进行小对象填充,这个小对象成为chunk,避免大量重复的初始化和清理,减轻了内存管理器的负担。
- Slab Allocation内存分配的原理是按照预先规定的大小,将分配给Memcached服务的内存预先分割成特定长度的内存块(chunk)分成组(chunks slab class),这些内存块不会释放,可以重复利用。
新增数据对象存储时。因Memcached服务器中保存这slab内空闲chunk的列表,他会根据该列表选择chunk,然后将数据缓存于其中。当有数据存入时,Memcached根据接收到的数据大小,选择最适合数据大小的slab分配一个能存下这个数据的最小内存块(chunk)。例如:有100字节的一个数据,就会分配存入下面112字节的内存块中,会有这样12字节被浪费,这部分空间就不能被使用了,这也是SlabAllocator机制的一个缺点。
Slab Allocator还可以重复使用已分配的内存,即分配道德内存不书房,而是重复利用。
Slab Allocation的主要术语
| Slab Allocation主要术语 | 注解说明 |
|---|---|
| slab class | 内存区类别(48bytes-1MB) |
| slab | 动态创建的实际内存区,即分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。slab默认大小为1048576byte(1MB),大于1MB的数据会忽略。 |
| slab classid | slab class的ID |
| chunk | 数据区块,固定大小,chunk初始大小,1.4版本中是48bytes |
| item | 实际存储在chunk中的数据项。 |
Slab内存管理机制特点
- 提前分配大量内存Slab 1Mb,再进行小对象填充chunk。
- 避免大量重复的初始化和清理,减轻内存管理器的负担。
- 避免频繁malloc/free内存分配导致的碎片。
下面对Mc内存管理机制进行一个小结
- mc的早期内存管理机制为malloc(动态分配内存)。
- malloc(动态内存分配)产生内存碎片,导致操作系统性能急剧下降。
- Slab内存分配机制可以解决内存碎片的问题
- Memcached服务的内存预先分割成特定长度的内存块,成为chunk,用于缓存数据的内存空间或内存块,相当于磁盘的block,只不过磁盘的每一个block都是相等的,而chunk只有在同一个Slab Class内才是相等的。
- Slab Class指特定大小(1MB)的包含多个chunk的集合或组,一个Memcached包含多个Slab Class,每个Slab Class包含多个相同大小的chunk。
- Slab机制也有缺点,例如,Chunk的空间会有浪费等。
5.2 Memcached Slab Allocator内存管理机制的缺点
chunk存储item浪费空间
Slab Allocator解决了当初的内存碎片问题,但新的机制也给Memcached带来了新的问题。这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如:将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了
避免浪费内存的方法是,预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀,这样就可以较少内存的浪费。
还有一种方法是,在启动时,指定-f参数,能在某种程度上控制内存组之间的大小差异。在应用中使用Memcached时,通常可以不重新设置这个参数,即默认值1.25进行部署即可。如果想优化Memcached对内存的使用,可以考虑重新计算数据的预期品均长度,调整这个参数来获得合适的设置值。
5.3 Memcached的检测过期与删除机制
5.3.1 Memcached懒惰检测对象的过期机制
首先要知道,Memcached不会主动检测item对象是否过期,而是在进行get操作时检查item对象是否过期自己是否应该删除!
因为不会主动检测item对象是否过期,自然也就不会释放已分配给对象的内存空间了,除非为添加的数据设定过期时间或内存缓存满了,在数据过期后,客户端不能通过key取他的值,起存储空前被重新利用。
Memcached使用的这种策略为懒惰检测对象过期策略,即自己不监控存入的key/value对是否过期,而是在获取key值时查看记录时间戳(set key flag exptime bytes),从而检查key/value对空间是否过期。这种策略不会在过期检测上浪费CPU资源
5.3.2 Memcached惰性删除对象机制
当删除item对象时,一般不会释放内存空间,而是做删除标记,将指针放入slot回收插槽,下次分配的时候直接使用。
Memcached在分配空间时,会优先使用已经过期的key/value对空间;若分配的内存空间占满,Memcached就会使用LRU算法来分配空间,删除最近最少使用的key/value对,从而将其空间分配给新的key/value对。在某些情况下(完整缓存),如果不想使用LRU算法,那么可以通过“-M”参数来启动Memcached,这样Memcached在内存耗尽时,会返回一本报错信息,如下:
-M return error on memory exhausted (rather than removing items)
Memcache删除机制小结:
不主动检测item对象是否过期,而是在get时才会检查item对象是否过期以及是否应该删除。
当删除item对象时,一般不释放内存空间,而是做删除标记,将指针放入slot回收插槽,下次分配的时候直接使用。
当内存空间满的时候,将会根据LRU算法把最近最少使用的item对象删除。
数据存入可以设定过期时间,但是数据过期后不会被立即删除,而是在get时检查item对象是否过期以及是否应该删除。
如果不希望系统使用LRU算法清楚数据,可以使用-M参数。
stats
STAT curr_items 3
STAT total_items 10 #←删除前的item对象
STAT evictions 0
END
flush_all
OK
stats
STAT pid 1532
...
STAT curr_items 3 #←由于memcached删除机制的原理,数据并未释放而是做了标记
STAT total_items 10 #←在下次访问过
STAT evictions 0
END
flush_all
OK
STAT curr_items 2
STAT total_items 6
STAT evictions 0
END
get a
END
stats
...
STAT bytes 67
STAT curr_items 1
STAT total_items 6
STAT evictions 0
END
# 数据过期与上述基本相同
set key 0 10 2
23
STORED
stats
..
STAT curr_items 1
STAT total_items 2
STAT evictions 0
END
get ket
END
stats
...
STAT curr_items 1
STAT total_items 2
STAT evictions 0
END
get key
END
stats
...
STAT curr_items 0
STAT total_items 2
STAT evictions 0
END
6 Memcache服务安装
6.1 Memcached 安装
Memcached的安装比较简单,支持Memcached的平台常见的有Linux、FreeBSD、Solaris、windows。这里以CentOS 7为例进行讲解。
6.1.1 安装libevent及连接Memcached工具nc
系统安装环境如下
$ cat /etc/redhat-release
CentOS Linux release 7.1.1503 (Core)
$ uname -r
3.10.0-229.el7.x86_64
$ uname -m
x86_64
安装Memcached前,需要先安装libevent,此处用yum安装libevent。
yum install libevent libevent-devel nc -y
# centos7 nc变更为nmap-ncat
6.1.2 编译安装Memcached
./configure --prefix=/app/memcached
make && make install
yum安装的Memcached版本略低,但是不影响使用。
# CentOS 6
$ yum list nc memcached
Loaded plugins: fastestmirror, security
Loading mirror speeds from cached hostfile
Available Packages
memcached.x86_64 1.4.4-3.el6_8.1 updates
nc.x86_64 1.84-24.el6 base
# CentOS 7
$ yum list memcached|grep memcached
memcached.x86_64 1.4.15-10.el7_3.1 updates
6.2 安装Memcached客户端
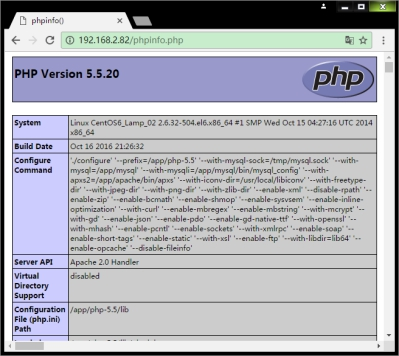
LAMP PHP环境准备
这里以PHP虚拟机程序为例,首先要在LAMP环境下能出来phpinfo信息页面,只有这样才能继续操作。具体如图:
6.2.1 PHP扩展插件Memcache与Memcached
PHP的Memcached扩展分为两个版本:
-
memcache 是 pecl 扩展库版本,原生支持php,出现于2004年。
-
memcached 是 libmemcached 版本,出现较后,是新一代,因此也更加完善,推荐使用。
在安装memcache扩展的时候并不要求安装其他依赖,但是在安装memcached的时候会要求你安装libmemcached,问题来了,libmemcached是memcache的C客户端,它具有的优点是低内存,线程安全等特点。比如新浪微博之前就全面将php的memcache替换成php的memcached,在高并发下,稳定性果断提高。差别比较大的一点是,memcached 支持 Binary Protocol,而 memcache 不支持,意味着 memcached 会有更高的性能。不过,还需要注意的是,memcached 目前还不支持长连接。
参考网址:http://blog.wpjam.com/m/memcache-vs-memcached/
6.2.2 PHP Memcache扩展安装
php的Memcache的扩展插件下载地址为:http://pecl.php.net/package/memcache
PHP的Memcache客户端扩展插件安装命令如下:
/app/php/bin/phpize
./configure --enable-memcache --with-php-config=/app/php/bin/php-config
make && make install
配置Memcache客户端,使其生效
修改PHP的配置文件php.ini,加入Memcache客户端的配置
extension=/app/php-5.5/lib/php/extensions/no-debug-non-zts-20121212/memcache.so
重启php fpm服务使php的配置修改生效
/app/php/sbin/php-fpm -t
打开浏览器访问phpinfo页面,出现下图表示Memcache客户端安装成功。
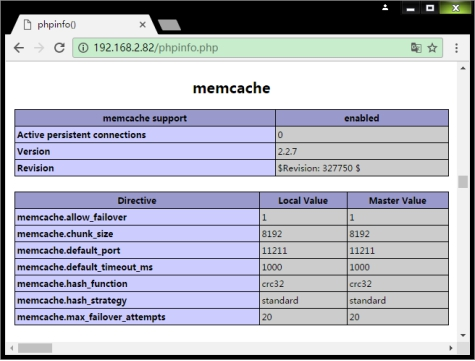
6.2.2 部署memcached
PHP Memcached 扩展基于 libmemcached 开发的,使用 libmemcached 库提供的 API 与 Memcached 服务进行交互。顾安装php memcached扩展需要先安装libmemcached
libmemcached下载地址:https://launchpad.net/libmemcached
安装libmemcached依赖包
yum install cyrus-sasl-devel -y
遇到如下错误:
configure: error: no, sasl.h is not available. Run configure with
--disable-memcached-sasl to disable this check
解决:需先安装后在编译libmemcached
yum install cyrus-sasl-devel -y
编译libmemcached:
./configure \
--with-memcached=/usr/local/memcached \
--prefix=/usr/local/libmemcached
安装PHP Memcached组件
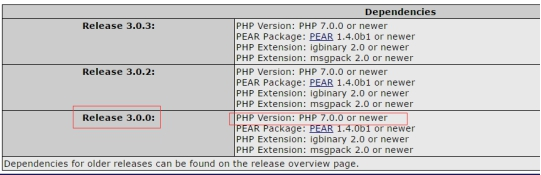
下载和解压这步,我们要区分是PHP7还是之前的版本:
下载网址:http://pecl.php.net/package,这里写名3.0版本之后,支持PHP版本为7.0或以上
编译参数
/app/php/bin/phpize
./configure \
--enable-memcached \
--with-php-config=/app/php-5.5/bin/php-config \
--with-libmemcached-dir=/app/libmem-1.0.18/
配置Memcache客户端,使其生效
修改PHP的配置文件php.ini,加入Memcache客户端的配置
extension=/app/php-5.5/lib/php/extensions/no-debug-non-zts-20121212/memcached.so
打开浏览器访问phpinfo页面,出现下图表示Memcached组件安装成功。
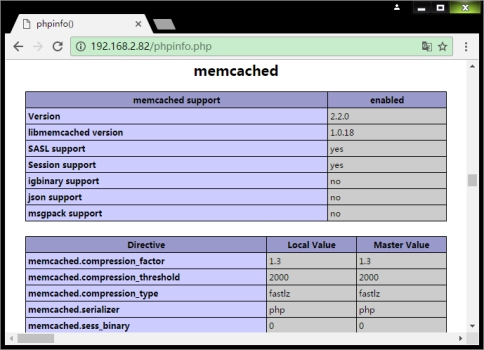
测试Memcache扩展与Memcached扩展
- 测试Memcache扩展是否成功
$m = new Memcache();
$m->connect('127.0.0.1',11211) or die('Could not connect');
$m->set('key2321','zhangsan');
echo $m->get('key2321');
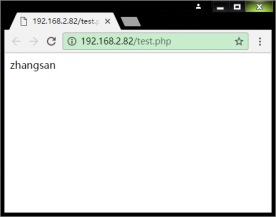
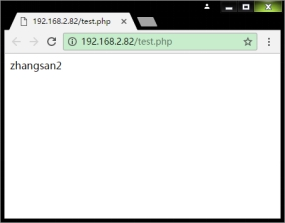
- 测试Memcached扩展是否成功
$m = new Memcached();
$m->addServer('127.0.0.1',11211,40);
$m->set('ke1','zhangsan2');
echo $m->get('ke1');
用telnet查询
$ telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
get key2321
VALUE key2321 0 8
zhangsan
END
get ke1
VALUE ke1 0 9
zhangsan2
END
参考网址:http://www.bcty365.com/content-103-3516-1.html
7 Memcached服务的基本管理
7.1 启动Memcached
启动Memcached的命令如下:
$ /home/memcached/bin/memcached -m 16m -p 11211 -d -u root -c 8192
查看启动状态
$ lsof -i:11211
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
memcached 16729 root 26u IPv4 139948 0t0 TCP *:memcache (LISTEN)
memcached 16729 root 27u IPv6 139949 0t0 TCP *:memcache (LISTEN)
memcached 16729 root 28u IPv4 139952 0t0 UDP *:memcache
memcached 16729 root 29u IPv4 139952 0t0 UDP *:memcache
memcached 16729 root 30u IPv4 139952 0t0 UDP *:memcache
memcached 16729 root 31u IPv4 139952 0t0 UDP *:memcache
memcached 16729 root 32u IPv6 139953 0t0 UDP *:memcache
memcached 16729 root 33u IPv6 139953 0t0 UDP *:memcache
memcached 16729 root 34u IPv6 139953 0t0 UDP *:memcache
memcached 16729 root 35u IPv6 139953 0t0 UDP *:memcache
配置ld.so.conf路径防止启动Memcached时报错
echo '/usr/local/lib' >>/etc/ld.so.conf
ldconfig
启动多个实例
memcached -m 16m -p 11212 -d -uroot -c 8192
查看结构
$ netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:11211 0.0.0.0:* LISTEN 16729/memcached
tcp 0 0 0.0.0.0:11212 0.0.0.0:* LISTEN 16741/memcached
tcp6 0 0 :::11211 :::* LISTEN 16729/memcached
tcp6 0 0 :::11212 :::* LISTEN 16741/memcached
udp 0 0 0.0.0.0:11211 0.0.0.0:* 16729/memcached
udp 0 0 0.0.0.0:11212 0.0.0.0:* 16741/memcached
udp6 0 0 :::11211 :::* 16729/memcached
udp6 0 0 :::11212 :::* 16741/memcached
7.2 Memcached启动相关参数说明
表7-1为Memcached启动命令相关参数说明
| 命令参数 | 说明 |
|---|---|
| 进程与连接参数 | |
| -d | 以守护进程(daemon)方式运行服务 |
| -u | 指定运行Memcached的用户,如果当前用户为root,需要使用此参数指定用户 |
| -l | 指定Memcached进程监听的服务器IP地址,可以不设置此参数。 |
| -p | 指定Memcached服务监听TCP端口号。默认为11211 |
| -P | 设置Memcached的PID文件($$),保存PID到指定文件 |
| 内存相关设置 | |
| -m | 指定Memcached服务可以缓存数据的最大内存,默认为64M |
| -M | Memcached服务内存不够时禁止LRU,如果内存满了会报错 |
| -n | 为key+value+flags分配的最小内存空间,默认为48节 |
| -f | chunk size增长因子,默认为1.25 |
| -L | 启用大内存页,可以降低内存浪费,改进性能。 |
| 并发连接设置 | |
| -c | 最大的并发连接数,默认是1024 |
| -t | 线程数,默认4,。由于Memcached采用的是NIO,所以太多线程作用不大 |
| -R | 每个event的最大请求,默认是20 |
| -C | 禁用CAS(可以禁止版本计数,减少开销) |
| 调试参数 | |
| -v | 打印较少的errors/warings |
| -vv | 打印非常多调试信息和错误输出到控制台,也打印客户端命令及相应 |
| -vvv | 打印极多的调试信息和错误输出,也打印内部状态转变 |
更多参数 memcached -h
7.3 向Memcached中写入数据。并检查
7.3.1 Memcached中的数据形式及与MySQL相关语句对比
向Memcached中添加数据时,注意添加的数据一般为键值对的形式,例如:key1-value1 key2-value2
这里把Memcached添加、查询、删除等的命令和MySQL数据库做了一个基本类比。见表7-2
| MySQL数据库管理 | Memcached管理 |
|---|---|
| MySQL的insert语句 | Memcached的set命令 |
| MySQL的select语句 | Memcached的get命令 |
| MySQL的delete语句 | Memcached的delete命令 |
管理MySQL和Memcached的常见命令类比
7.3.2 向Memcached中写入数据实践
通过printf配合nc想Memcached中写入数据
$ printf "set key1 0 0 6\r\nzhang\r\n"|nc 127.0.0.1 11211
$
如果set命令的字节是6就要6个字符(字节)。否则插入数据就不会成功
$ printf "set key1 0 0 6\r\nzhangs\r\n"|nc 127.0.0.1 11211
STORED
通过printf配合nc从Memcached中读取数据,命令如下:
$ printf "get key1\r\n"|nc 127.0.0.1 11211
VALUE key1 0 6
zhangs # 这就是读到的key1对应额值
END
通过printf配合nc从Memcached中删除数据
$ printf "delete key1\r\n"|nc 127.0.0.1 11211
DELETED #←出现DELETED表示成功删除key1及对应的数据
$ printf "get key1\r\n"|nc 127.0.0.1 11211
END
⚠ 提示:推荐使用上述方法测试操作Memcached
通过telnet命令写入数据时,具体步骤如下。
通过telnet向Memcached写入数据
$ telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
add id 0 0 5
12345 #← 写入数据
STORED
add id 0 0 3
123
NOT_STORED #← 若key存在则报如下错误
set name 0 0 6 #← 写入数据,如果key不存在则创建key,如果存在则更改key的value值
张三 #← 中文,每个字占3个bytes
STORED
get name
VALUE name 0 6
张三
END
get id
VALUE id 0 5
12345
END
set id 0 0 1 #← 写入数据,如果key不存在则创建key,如果存在则更改key的value值
2
STORED
get id
VALUE id 0 1
2
END
incr/decr
set key 0 0 1
9
STORED
get key
VALUE key 0 1
9
END
incr key 1
10
get key
VALUE key 0 2 #← 对整型增加后对应的bytes也增加
10
END
get key
VALUE key 0 1
1
END
decr key 1
0
decr key 1
0
⚠ 提示:telnet连接后如果输入字符错了,可以通过Ctrl+Backspace删除
7.3.3 操作Memcached相关命令的语法
以下为操作Memcached的相关命令基础语法
set key1 0 0 6
[command name] [key] [flags] [exptime] [bytes]
[datablock]\r\n
[status]\r\n
表7-3 Memcached相关命令详细说明
| 命令 | 说明 |
|---|---|
| command name | set:无论如何都进行写入数据,会覆盖老数据 add:只有对应数据不存在时才添加数据 repalce:只有数据存在时进行替换数据 delete [second] 加秒数之后,被删除的key N秒内不能再用,作用:让网站的页面也代谢完毕 append往后追加:prepend[key]datablock[status]? prepend往前追加:prepend[key]datablock[status] cas按版本号更换 incr key num 增加一个值的大小。 decr key num 减少一个值的大小。 incr decr操作将值进行32位无符号计算 0-232-1范围内 应用场景,限时秒杀中库存量,先给抢中者分发订单号,数据低谷期将数据写入数据库 |
| key | 普通字符串,要求小于250个字符,不包含空格和控制字符 |
| flags | 客户端用来标识数据格式和数值,如json、xml、压缩、数组等 |
| exptime | 存活时间s, 0为永久有效:编译时默认为30天。 小于30天,60x60x24x30为秒数, 大于30天为unix timestamp 如:团购网站,某团到中午12:00失效。 |
| bytes | byte字节数,不包含\r\n,根据长度截取存/取的字符串,可以是0,即存空串 |
| datablock | 文本行,以\r\n结尾,当然可以包含\r或\n |
| status | STORED/NOT_STORED/EXISTS/NOT_FOUND ERROR/CLIENT_ERROR/SERVER_ERROR服务器端会关闭连接以修复。 |
事例1:向memcached中插入数据
add id 0 0 5
12345
STORED
set name 0 0 6
张三
STORED
get name
VALUE name 0 6
张三
END
get id
VALUE id 0 5
12345
END
set id 0 0 1
2
STORED
get id
VALUE id 0 1
2
END
7.3.4 关闭Memcached
单实例关闭Memcached的方法如下:
killall memcached 或 pkill
若启动了多个实例Memcached,使用killall或pkill方式就会同时关闭这些实例!因此最好在启动时增加-P参数指定固定的pid文件,这样便于管理不同的实例。实例如下
memcached -m 16m -p 11211 -d -u root -c 8192 -P /var/run/memcached/11211.pid
memcached -m 16m -p 11211 -d -u root -c 8192 -P /var/run/memcached/11212.pid
此时,即可以通过kill命令关闭Memcached
kill `cat /var/run/memcached/11211.pid`
关闭Memcached的方法小结如下:
ps -ef|grep memcached|grep -v grep|awk '{print $2}'|xargs kill
kill `cat /var/run/memcached/11211.pid`
pkill memcached
killall memcached
7.3.5 企业工作场景中如何配置Memcached
在企业实际工作中,一般是开发人员提出需求,说要不熟一个Memcached数据缓存。运维人员在接到这个不确定的需求后,需要和开发人员深入沟通,进而确定要将内存指定为多大,或者和开发人员商量如何根据具体业务来指定内存缓存的大小。此外,还要确定业务的重要性,进而决定是否采取负载均衡、分布式缓存集群等架构,最后确定使用多大的并发连接数等。
对于运维人员,部署Memcached一般就是安装Memcached服务端,把服务启动起来,最好监控,配好开机自启动,基本上就OK了,客户端的PHP程序环境一般在安装LNMP环境时都会提前安装Memcached客户端插件,Java程序环境下,开发人员会用第三方的JAR包直接连接Memcached服务。
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2016/09/memcached/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。