本文发布于Cylon的收藏册,转载请著名原文链接~
Linux文件数据同步方案
在讲解MySQL主从复制之前,先回忆下,前面将结果的普通文件(磁盘上的文件)的同步方法。
文件级别的异机同步方案
- scp/sftp/nc命令可以实现远程数据同步。
- 搭建ftp/http/svn/nfs服务器,然后在客户端上也可以把数据同步到服务器。
- 搭建samba文件共享服务,然后在客户端上也可以把数据同步到服务器。
- 利用rsync/csync2/union等均可以实现数据同步。
提示:union可实现双向同步,csync2可实现多机同步。
以上文件同步方式如果结合定时任务或innotify sersync等功能,可以实现定时以及实时的数据同步。
-
扩展思想:文件级别复制也可以利用mysql,mongodb等软件作为容器实现。
-
扩展思想:程序向两个服务器同时写数据,双写就是一个同步机制。
特点:简单、方便、效率和文件系统级别要差一些,但是被同步的节点可以提供访问。
- 软件的自身同步机制(mysql、oracle、mongdb、ttserver、redis…..),文件放到数据库,听不到从库,再把文件拿出来。
文件系统级别的异机同步方案
drbd基于文件系统同步,相当于网络RAID1,可以同步几乎任何业务数据。
mysql数据的官方推荐drbd同步数据,所有单点服务例如:NFS,MFS(DRBD),MySQL等度可以用drbd做复制,效率很高,缺点:备机服务不可用。
数据库同步方案
- 自身同步机制:mysql relication,(逻辑的SQL重写)物理复制方法drbd(丛库不提供读写)。
- 第三方drbd
MySQL主从复制概述
MySQL的主从复制方案,和上述文件及文件系统级别同步是类似的,都是数据的传输。只不过MySQL无需借助第三方工具,而是其自带的同步复制功能,另外一点,MySQL的主从复制并不是磁盘上文件直接同步,而是逻辑的binlog日志绒布到本地在应用执行的过程
MySQL主从复制是一个异步的复制过程(虽然一般情况下感觉是实时的),数据将从一个MySQL数据库(Master)复制到另一个数据库(Slave),在 mater 与 Slave之 间实现整个主从复制的过程是由三个线程参与完成的。其中有两个线程( SQL和IO )在Slave端,另外一个线程(I/O)在Master端。
要实现MySQL的主从复制,首先必须打开 Master 端的 binlog 记录功能,否则就无法实现。因为整个复制过程实际上就是Slave从Master端获取Binlog日志,然后在Slave上以相同顺序逐自获取 binlog 日志中所记录的各种SQL操作。
要打开MySQL的binlog记录功能,可能通过在MySQL的配置文件 my.cnf 中的 mysqld 模块( [mysqld] )标识后的参数部分增加 “log-bin” 参数选项来实现,具体信息如下:
[mysqld]
log-bin = /data/3307/mysql-bin
提示:log-bin需放置在[mysqld]标识后,否则会导致配置复制不成功。
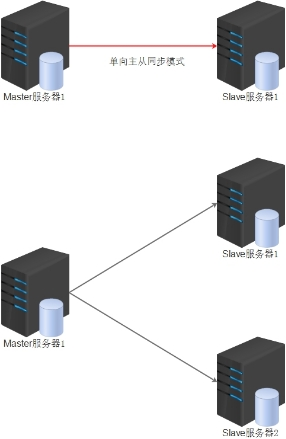
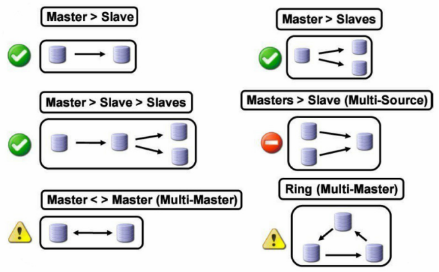
MySQL数据可支持单向、双向、链式级联等不同场景的复制。在复制过程中,一台服务器充当主服务器(Master),而一个或多个其他的服务器充当从服务器(Slave)。
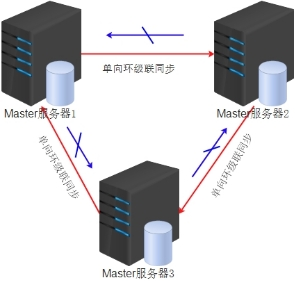
复制可以使单向:M==>S,也可以是双向 M<==>M,当然也可以多M环装同步等。
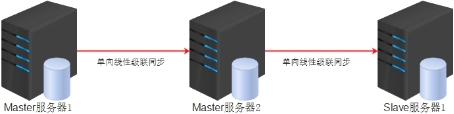
如果设置了链式级联复制,那么,从(slave)服务器本身除了充当从服务器外,也会同时充当其下面从服务器的主服务器。链式级联复制类似 A==>B==>C==>D 的复制形式。
下面是MySQL各种同步架构的逻辑图。
单向主从复制逻辑图,次架构只能在Master端进行数据写入。官方给出Slave最多9,工作中不要超过5
双向主主同步逻辑图,次架构可以再Master1端或Master2端进行数据写入

线性级联单向双主同步逻辑图,此架构只能在Master1端进行数据写入
缺陷:1 ==>3 之间会存在延迟
环装级联单向多主同步逻辑图,任意一个点都可以写入数据。
环装级联单向多主多从同步逻辑图,次架构只能在任意一个Master端进行数据写入。
应对读比较多的情况,将所有的从做成负载均衡,三个主做负载均衡。如果其中一个主断掉,其从节点就成了旧数据
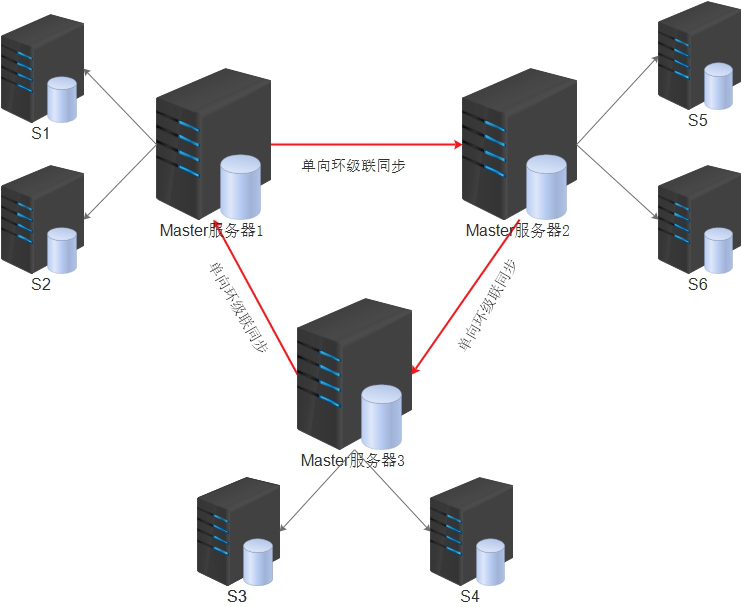
MySQL官方同步架构图
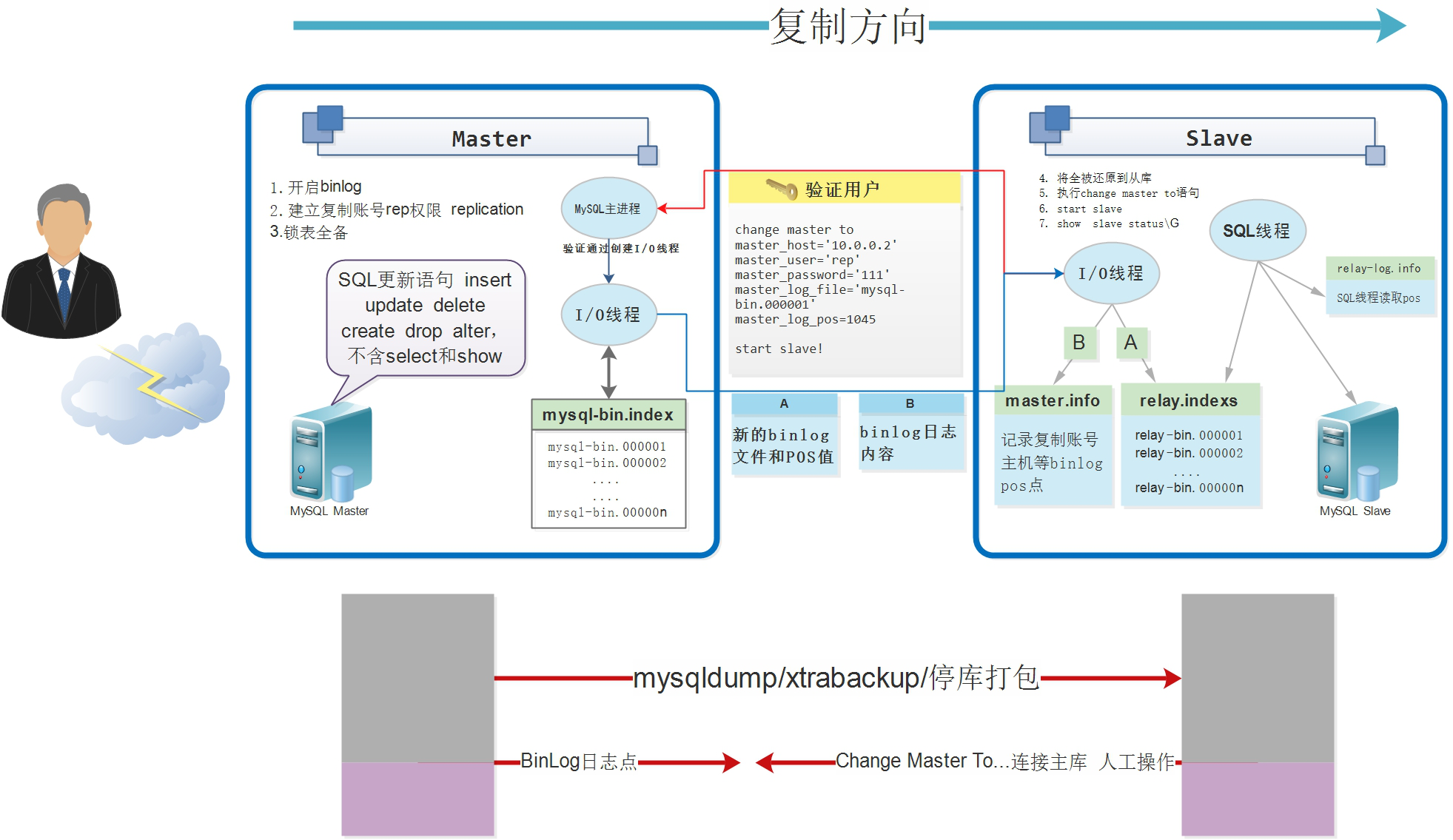
MySQL主从复制过程原理
下面简单描述下MySQL Replication的复制原理过程
- 在 Slave 服务器上执行
start slave命令开启主从复制开关,主从复制开始进行。 - 此时,Slave服务器的 I/O线程 会通过在Master上已经授权的复制用户权限请求连接 Master 服务器,并请求从指定 binlog 日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change master命令指定的)之后开始发送binlog日志内容。
- Master服务器接受到来自 Slave服务器 I/O线程 的请求后,其上负责复制的I/O线程会根据Slave服务器I/O线程请求的信息分批读取指定 Binlog 日志文件指定位置之后的 Binlog 日志信息,然后返回给 Slave 端的 I/O线程。返回的信息中除了 Binlog 日志内容外,还有在Master服务器端记录的新的Binlog文件以及在新的Binlog中的下一个指定更新位置。
- 当Slave服务器的 I/O线程 发送的日志内容及日志文件及位置后,会将 Binlog日志 内容依次写入到 Slave 端自身的 Relay Log(即中继日志)(mysql-relay-bin_xxxxx)端新binlog日志时,能告诉master端服务器需要从新Binlog日志的指定文件及位置开始请求新的binlog日志内容
- Slave服务器端的SQL线程会实时地检测本地 Relay Log 中 I/O线程 新增加的日志内容,然后及时地把 Relay Log 文件中的内容解析成SQL语句,并在自身 Slave服务器 上按解析SQL语句的位置顺序执行应用这些SQL语句,并记录当前应用中继日志的文件名及位置点在 **
relay-log.info**中。
经过了上面的过程,就可以确保在Master端和Slave端执行了同样的SQL语句。当复制状态正常的情况下,Master端和Slave端的数据是完全一样的。当然,MySQL的复制机制也有一些特殊情况,具体请参考官方的说明。
MySQL主从复制原理小结:
- 主从复制是异步的逻辑SQL语句级的复制。
- 复制时,主库有一个I/O线程,从库有两个线程I/O和SQL线程。
- 实现主从复制的必要条件是主库要开启记录binlog功能。
- 作为复制的所有MySQL节点的server-id都不能相同
- binlog文件只记录对数据库有关的SQL(来自主数据库内容的变更),不记录任何查询(select show)语句。
MySQL主从复制配置
环境准备
MySQL主从复制实践对环境的要求比较简单,可以是单机单数据库多实例的环境,也可以是两台服务器,每个机器上独立数据库的环境。
$ ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 \*:3306 \*:\*
LISTEN 0 128 \*:3307 \*:\*
提示:这里把3306实例作为主库,3307实例作为从库,如果根据前面的内容配置了mysql多实例环境,直接开启多实例环境使用即可。
定义主从复制需要的服务器角色
主库及从库IP、端口信息:
- master: 192.168.2.110:3306
- slave: 192.168.2.110:3307
这里的主从复制技术是针对前面的内容以单机数据库多实例环境来讲的。一般情况下,小企业在做常规的主从复制时,主从服务器多数在不同的机器上,并且监听的端口均为默认的3306。虽然不在同一个机器上,但是步骤和过程却是一样的。
主库部分配置
设置server-id值并开启binlog功能参数
根据前文介绍的MySQL主从复制原理我们知道,要实现主从复制,关键是要开启binlog日志功能,所以,首先来打开主库的binlog参数。
[mysqld]
server-id=1 # <=用于同步的每台机器或实例server-id都不能相同
log-bin=/data/3306/mysql-bin #<=该部分可省略
提示:
-
上面的两个参数要放在my.cnf中的
[mysqld]模块下,否则会出错。 -
server-id的值使用服务器ip地址最后一个小数点后面数字如:19,目的是避免不同机器或实例ID重复(不适合多实例) 0 < server-id < 232-1的自然数 -
要先在
my.cnf配置文件中查找相关参数,并按要求修改。若不存在再添加参数。切记参数不能重复 -
修改my.cnf配置后需要重启数据库,命令为:
/data/3306/mysql restart,要确认真正重启了
检查配置参数后的结果
$ grep -E 'log-bin|server-id' my.cnf
log-bin = /data/3306/mysql-bin
server-id = 1
登陆数据库检查参数的更改情况(需重启)
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 1 |
+---------------+-------+
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
在主库上建立用于主从复制的账号
根据主从复制的原理,从库要想和主库同步,必须有一个可以连接主库的账号,并且这个账号是主库上创建的,权限是允许主库的从库连接并同步数据。
登陆3306实例猪数据库
mysql -uroot -p111 -S /data/3306/mysql.sock
建立用于从库复制的账号rep:
grant replication slave on *.* to 'rep'@'192.168.2.%' identified by '1234';
# relication slave为mysql同步的必须权限,此处不要授权all
# *.*表示所有库所有表,也可以指定具体的库和表进行复制,例如shop.test
# rep@'192.168.2.%'为同步账号。192.168.2.%为授权网段,使用%表示192.168.2.0网段以rep用户访问
# identified by '1234' 为密码。生产环境要使用复杂密码
mysql> flush privileges;
检查主库复制账号权限
mysql> show grants for rep@'192.168.2.%'\G
*************************** 1. row ***************************
Grants for rep@192.168.2.%: GRANT REPLICATION SLAVE ON *.* TO 'rep'@'192.168.2.%' IDENTIFIED BY PASSWORD '*A4B6157319038724E3560894F7F932C8886EBFCF'
实现对数据库锁表只读
1. 对主数据库锁表只读(当钱窗口不要关闭)的命令:
flush table with read lock;
# 锁表后新建窗口查看mysql此时是不能插入数据的
提示:在引擎不同的情况,这个锁表命令的时间会受下面参数的控制。锁表时,如果草果设置时间不操作会自动解锁。
默认情况下自动解锁的市场参数值如下:
mysql> show variables like '%timeout%';
+----------------------------+----------+
| Variable_name | Value |
+----------------------------+----------+
| interactive_timeout | 28800 |
| wait_timeout | 28800 |
+----------------------------+----------+
2. 锁表后查看主库状态。可通过当前binlog日志文件名和二进制binlog日志偏移量来查看
注意,show master status;命令显示的信息要记录在案,后面的从库导入全备后,继续和主库复制时就是要从这个位置开始。
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000319 | 331 | | |
+------------------+----------+--------------+------------------+
mysql -uroot -p111 -S /data/3306/mysql.sock -e 'show master status;'
3. 锁表后,一定要单开一个新的SSH窗口,导出数据库的所有数据,如果数据量很大( 50GB+ ),并且允许停机,可以停库直接打包数据文件迁移,那样还快些
mysqldump -uroot -p111 \
-S /data/3306/mysql.sock \
--events -A -B|gzip >bak.`date +%F.sql.gz`
为了确保导出数据期间,数据库没有数据插入,导库完毕可以再检查下主库状态信息。
$ mysql -uroot -p111 -S /data/3306/mysql.sock -e 'show master status;'
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000319 | 331 | | |
+------------------+----------+--------------+------------------+
# 若无特殊情况,binlog文件及位置点和锁表后导出数据前是一致的,即没有变化的。
导出数据后,解锁主库,恢复可写,因为主库还要对外提供服务,不能一直锁定不让用户访问。
unlock tables;
# 此时新窗口的写入语句会立刻写入数据
实际上做从库前,无论主库更新多少数据库,最后从库都可以从上面show master status的位置很快赶上主库的进度的。
将导出数据迁移到从库
常用scp rsync等,将备份的数据往异地拷贝。
这里是多实例的主从配置,mysqldum p备份的3306实例的数据和要恢复的3307实例在一台机器上,因此无需异地复制拷贝了,
1. 设置server-id并关闭binlog功能
数据库的server-id一般在一套主从复制体系内是唯一的,这里从库的server-id要和主库及其他的从库不同,并且要注释掉从库的binlog参数,如果从库不做级联复制,并且不做备份用,就不要开启binlog,开启了反而会增加从库磁盘I/O等压力。
如下两种情况需要打开 binlog 功能,记录数据更新的SQL语句
级联同步 A=>B=>C中间的B时,就要开启binlog
在从库做数据库备份,数据库备份必须要有全备和binlog日志,才是完整的备份。
$ grep -E 'server-id|log-bin' my.cnf
#log-bin = /data/3307/mysql-bin
server-id = 3
提示:
-
参数要放在 my.cnf 中的
[mysqld]模块下,否则会出错。 -
server-id的值可使用服务器ip地址最后一个数字。
-
要先在文件中查找相关参数按要求修改。若发现不存在,再添加参数,切记参数不能同步。
-
修改完配置后需重启数据库。
2. 登陆数据库查看参数改变情况
$ mysql -uroot -S /data/3307/mysql.sock -e 'show variables like "log_bin";';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF |
+---------------+-------+
3. 将全备恢复到从库
mysql -uroot -p111 -S /data/3307/mysql.sock < bac.sql
提示:如果备份时使用了-A参数,则在还原数据到3307实例时,登陆3307实例的密码也回合3306主库一致,因为3307的授权表mysql也被覆盖了
4. 登陆3307从库,配置复制参数
CHANGE MASTER TO
MASTER_HOST='192.168.2.110',
MASTER_PORT=3306,
MASTER_USER='rep',
MASTER_PASSWORD='1234',
MASTER_LOG_FILE='mysql-bin.000322',
MASTER_LOG_POS=188;
CHANGE MASTER TO
MASTER_LOG_FILE='mysql-bin.000322',
MASTER_LOG_POS=107;
提示:字符串用单引号括起来,数值不用引号,密码需要。内容前后不能用空格
主从复制是不是成功,其中最关键的为下面三项状态参数:
$ mysql -uroot -S /data/3307/mysql.sock -e 'show slave status\G
'|grep -E 'IO_Running|SQL_Running|Seconds_Behind'
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Seconds_Behind_Master: 0
Slave_IO_Running: Yes,这个是I/O线程状态,I/O线程负责从从库去主库读取binlog日志,并写入从库的中继日志中,状态为Yes表示I/O线程工作正常。Slave_SQL_Running: Yes,这个是SQL线程状态,SQL线程负责读取中继日志(relay-log)中的数据并转换为SQL语句应用到丛库数据库中,状态为Yes表示I/O线程工作正常。Seconds_Behind_Master: 0,这个是在复制过程中,丛库比主库延迟的秒数,这个参数很重要,但企业里更准确的判断主从延迟的方法为:在主库写时间戳,然后从库读取时间戳和当前数据库时间的进行比较,从而认定是都延迟。
有关show slave status结果的说明。请参考MySQL手册。
MySQL主从复制配置步骤小结
MySQL主从复制配置完整步骤如下:
- 准备两台数据库环境或者单台多实例环境,确定能正常启动和登陆。
- 配置my.cnf文件:主库配置
log-bin和server-id参数,从库配置server-id,该值不能和主库及其他从库一样,一般不开启从库log-bin功能。注意,配置参数后要重启才能生效。 - 登陆主库增加从库连接主库同步的账户,例如:rep,并授权replication slave同步的权限。
- 登陆主库,整库锁表
flush table with read lock(关闭窗口后失效,超时时间到了锁表也失效),然后show master status查看binlog的位置状态。 - 新开窗口,在Linux命令行备份导出原有的数据库数据,并拷贝到丛库所在的服务器目录。如果数据库数据量很大,并且允许停机,可以停机打包,而不用mysqldump。
- 导出主库数据后,执行
unlock tablesl;解锁主库。 - 把主库导出的数据库恢复到从库。
- 根据主库的
show master status查看到binlog的位置状态,在从库执行change master to语句 - 从库开启复制开关即执行
start slave。 - 从库
show slave status\G
快速配置MySQL主从复制
步骤
- 安装好要配置从库的数据库,配置好
log-bin和server-id参数 - 无需配置主从库
my.cnf文件,主库log-bin和server-id参数默认就是配置好的。 - 登陆主库,增加从库链接主库同步的账户,例如:rep,并授权
replication slave同步的权限。 - 使用在半夜通过定时任务备份
mysqldump带-x和--master-date=1的命令及参数的全备数据,恢复到从库 - 在从库执行
change master to..语句,无需binlog文件及对应位置点。 - 从库开启同步开关,
start slave - 从库
show slave status\G,检查同步状态,并在主库进行更新测试。
MySQL主从复制线程状态说明及用途
MySQL主从复制主库I/O线程状态说明
登陆主数据库查看MySQL线程的同步状态。
mysql> show processlist\G;
*************************** 1. row ***************************
Id: 7
User: rep
Host: 192.168.2.110:39610
db: NULL
Command: Binlog Dump
Time: 57983
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
*************************** 2. row ***************************
Id: 11
User: rep
Host: 192.168.2.110:39614
db: NULL
Command: Binlog Dump
Time: 21942
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
*************************** 3. row ***************************
Id: 16
User: root
Host: localhost
db: information_schema
Command: Query
Time: 0
State: NULL
Info: show processlist
3 rows in set (0.00 sec)
ERROR:
No query specified
# 上述两个从库,每个从库对应一个I/O线程
提示:上述状态的意思是线程已经从binlog日志读取所有更新,并已经发送到了从数据库服务器,线程现在为空闲状态,等待由主服务器上二进制日志中的新事件更新
下表列出主服务器的 binlog Dump线程中State列的最常见状态。如果没有在主服务器上看见任何Binlog Dump线程,则说明复制没有在运行,二进制binlog日志由各种事件组成,一个事件会通常为一个更新加一些其他信息。
| 状态 | 说明 |
|---|---|
| Sending binlog event to slave | 线程已经从二进制binlog读取了一个事件并且正将它发送到从服务器 |
| Finished reading on binlog switching to next binlog | 线程已经读完二进制binlog日志文件,并且正在打开下一个要发送到从服务器的binlog日志文件 |
| Has sent all binlog to slave;waiting for binlof to be update | 线程已经从binlog日志读取所有的更新并已经发送到了从数据库服务器。线程现在为空闲状态,等待由主服务器上二进制binlog日志中的新事件更新。 |
| Waiting to finalize termination | 线程停止时发生了一个简单的状态 |
登陆从数据库查看mysql线程工作状态,从库有两个线程,即I/O和SQL线程。
下面是从I/O线程的状态。
mysql> show processlist\G
*************************** 1. row ***************************
Id: 7
User: system user
Host:
db: NULL
Command: Connect
Time: 33004
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 8
User: system user
Host:
db: NULL
Command: Connect
Time: 3510
State: Slave has read all relay log; waiting for the slave I/O thread to update it
Info: NULL
*************************** 3. row ***************************
下表列出了从库服务器的I/O线程的state列的最常见的状态。该状态也出现在Slave_IO_State列,有show slave status;显示
| 从库I/O线程工作状态 | 解释说明 |
|---|---|
| Connecting to master | 线程正试图连接主服务器 |
| Checking master version | 同主服务器之间建立连接后临时出现的状态 |
| Registering slave on master | |
| Requesting binlog dump | 建立同主服务器之间的连接后立即临时出现的状态。线程向主服务器发送一条请求,索取从请求的二进制binlog日志文件名和位置开始的二进制binlog日志的内容。 |
| Waiting to reconnect after a failed binlogdump request | 如果二进制binlog日志转储请求失败,线程进入睡眠状态,然后定期尝试重新连接。可以使用–master-connect-retry选项指定重试之间的间隔。 |
| Reconnect after a failed binlog dump request | 线程正尝试重新连接主服务器。 |
| Waiting for master to sent event | 线程已经连接上主服务器,正等待二进制binlog日志事件到达。 |
| Queueing master event to the relay log | 线程已经读取一个事件,正将它复制到中继日志供SQL线程来处理 |
| Reconnecting after failed master event read | 线程正尝试重新连接主服务器。当连接重新建立后,状态变为 Waiting for master to send event |
下面是从库SQL线程的状态
*************************** 2. row ***************************
Id: 8
User: system user
Host:
db: NULL
Command: Connect
Time: 5460
State: Slave has read all relay log; waiting for the slave I/O thread to update it
Info: NULL
| 从库SQL线程状态 | 解释说明 |
|---|---|
| Reading event from the relay log | 线程已经从中继日志读取一个事件,可以对事件进行处理了。 |
| Has read all relay log;waiting for the slave I/O thread to update it | 线程已经处理了中继日志文件中的所有事件,现在正等待I/O线程将新事件写入中级日志。 |
| Waiting for slave mutex on exit | 线程停止时发生的一个很简单的状态。 |
更多状态在mysql手册6.3章节
查看MySQL线程同步状态的用途
故障1:主库show master status;没返回状态结果
mysql> show master status;
Empty set (0.00 sec)
解答:上述问题原因是主库binlog功能没有开启或没生效
故障2:出现Last_IO_Error:Got fatal error 1236 from master when reading date from binary log:’’
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file'
原因:
- 主库停机导致binlog错误
- 从库执行change master命令时某一个参数的值多了空格,因而产生错误
解决方法
flush logs;
show master status;
slave start;
show slave status \G
故障3:Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids;
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the --replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it).
原因sever-id与主一致,更改后重启服务器恢复。
工作中MySQL从库停止复制故障案例
模拟重现故障的能力是运维人员最重要的能力。先从从库创建一个库,然后去主库创建同名的库来模拟数据冲突。
mysql> show slave status\G;
....
....
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1007
Last_SQL_Error: Error 'Can't create database 'test123'; database exists' on query. Default database: 'test123'. Query: 'create database test123 default character set utf8'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
对于该冲突,解决方法1:
stop slave; # 临时停止同步开关
set global sql_slave_skip_counter=1;# 将同步指针想下移动一个,如果多次不同步,可以重复操作
start slave;
mysql> show slave status\G
....
....
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
对于普通的互联网业务,上述的移动指针的命令操作带来的问题不是很大。当然要确认不影响公司业务的前提下。
若是在企业场景下,对当前业务来说,解决主从同步比主从不一致更重要,如果主从数据一致也是很重要的,那就再找个时间恢复下这个从库。
主从数据不一致更重要还是保持主从同步持续状态更重要,则要根据业务选择。
这样Slave就会和Master同步了,其关键点为:
Slave_IO_Running:Yes
Slave_SQL_Running:Yes
Senconds_Behind_Master # 是否为0 0表示已经同步状态
提示:``set global sql_slave_skip_counter=n` n取值>0,忽略执行N个更新。
解决方法2:根据可以忽略的错误号事先在配置文件中配置,跳过指定的不同映像业务数据的错误,例如:
slave-skip-errors=1032,1062,1007
提示:类似由于入库重复导致的失败可以忽略,其他情况是不是可以忽略需要根据不同送死的具体业务来评估
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
....
....
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
....
....
Last_SQL_Errno: 1007
Last_SQL_Error: Error 'Can't create database 'zhangsan'; database exists' on query. Default database: 'zhangsan'. Query: 'create database zhangsan'
其他可能引起复制故障的问题:
MySQL自身的原因及认为重复插入数据。
不同的数据库版本会引起不同步,低版本到高版本可以,但是高版本不能往低版本同步。
MySQL的运行错误或者程序BUG。
binlog记录模式,例如:row level模式就比默认的语句模式要好。
让MySQL从库记录binlog日志方法
从库需要记录binlog的应用场景为:当前的从库还要作为其他从库的主库,例如:级联复制或双主互为主从场景的情况下。从库记录binlog日志的方法:
在从库的 my.cnf 中加入如下参数,然后重启服务生效即可。
log-slave-updaes # 必须要有这个参数
log-bin=/data/3306/mysql-bin
expire_logs_days=7 # binlog日志过期参数,过期自动删除
MySQL主从复制集群架构的数据备份策略
有了主从复制了,还需要做定时全量加增量备份么?答案是肯定的
因为,如果主库有语句级误操作(例如:drop database test; ),从库也会这行 drop database test; ,这样MySQL主从库就都删除了该数据。
把从库作为数据库备份服务器时,备份策略如下:
- 高并发业务场景备份时,可以选择在一台数据库上备份(Slave5),把从库作为数据库备份服务器时需要在从库开启
binlog功能,如图所示
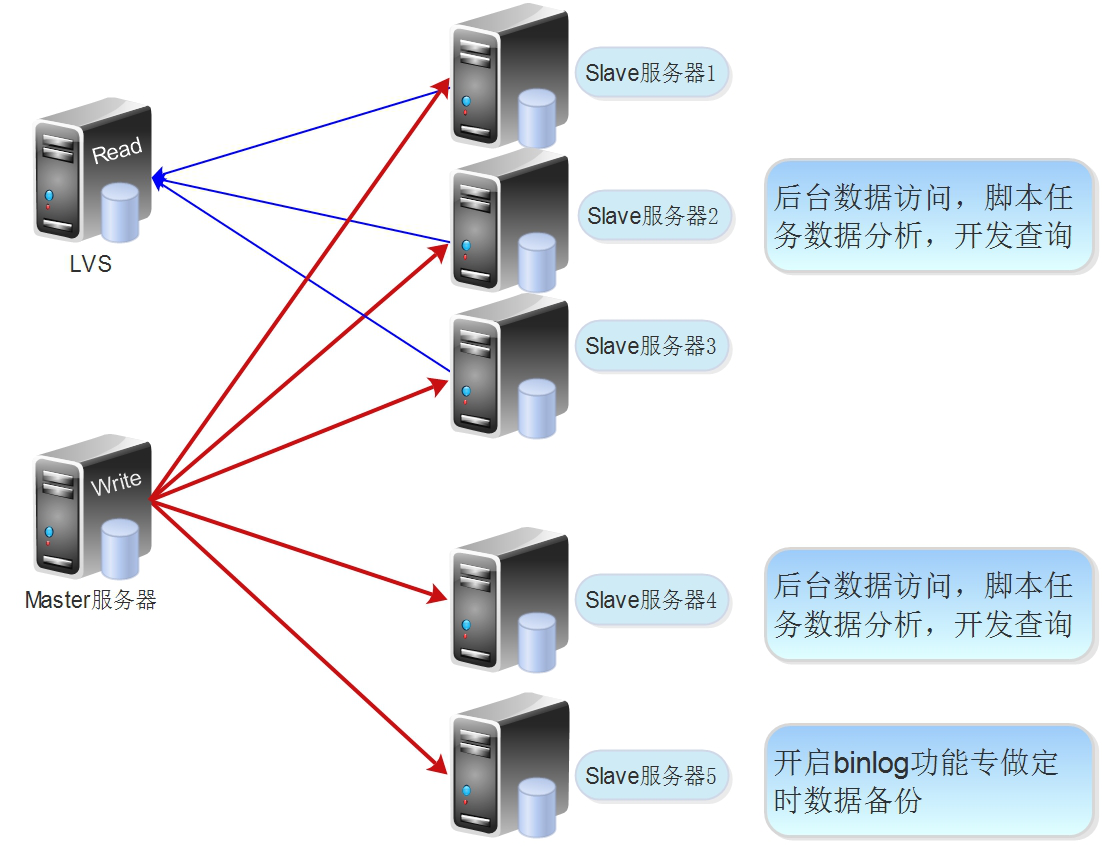
步骤如下
- 选择一个不对外提供服务器的从库,这样可以确保和主库更新最接近,专门做数据备份用。
- 开启从库binlog功能。
备份时可以选择只停止 SQL 线程,停止应用SQL语句到数据库,I/O线程保留工作状态,执行命令为 stop slave sql_thread; ,备份方式可以采取 mysqldump 逻辑备份或者直接物理备份,例如:cp tar(打包目录)工具,或 xtrabackup(第三方的物理备份软件)进行备份,逻辑备份和物理备份的选择,一般是根据总的本分数据了多少进行选择,数据量低于20G,建议选择 mysqldump 逻辑备份方法,安全稳定,最后把全备和 binlog 数据发总到备份服务器上留存
MySQL主从复制延迟问题原因及解决方案
问题一:一个主库的从库太多,导致复制延迟
建议从库数量3-5个为宜,要复制的节点数量过多,会导致复制延迟。
问题二:从库硬件比主库差,导致复制延迟
查看master和slave的系统配置,可能会因为机器配置的问题,包括磁盘IO、CPU内存等各方面因素曹成复制的延迟,一般发生在高并发大数据量写入场景。
问题三:慢查询SQL语句过多
假如一条SQL语句,执行时间是20秒,那么从执行完毕,到从库上能查到数据也至少是20秒,这样就延迟了20秒
SQL语句的优化一般要作为常规工作不断的监控和优化,如果是单个SQL的写入时间长,可以修改后分多次写入,通过查看慢查询日志或 show full processlist 命令找出执行时间长的查询语句或者大的事务。
问题四:主从复制的设计问题
例如,主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟,更高版本的MySQL可以支持多线程复制(MySQL5.6 Mariadb10.0),门户网站则会自己开发多线程同步功能。
问题五:主从之间的网络延迟
主从库的网卡,网线,链接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟。另外,跨公网主从复制很容易导致主从复制延迟。
问题六:主库读写压力大,导致复制延迟
主库的硬件要搞好一些,架构的前端要加buffer以及缓存层。
通过read-only让主库只读访问
read-only参数选项可以让出服务器只允许来自从服务器线程或具有SUPER权限的数据库用户进行更新。可以确保从服务器不接受来自用户端的非法用户更新。
read-only参数允许数据库更新的条件为:
- 具有SUPER权限的用户可以更新,不收read-only参数影响。例如:管理员root(注:工作中用户连接的账号授权不要给all,这样可以防止用户写数据)
- 来自从服务器线程可以更新,不收read-only参数影响,例如,前文的rep用户,在生产环境中,可以再从库Slave中使用read-only参数,确保从库数据不被非法更新。
read-only参数配置方法如下
方法一:启动数据库时直接带–read-only参数启动或重启使用
killall mysqld
mysqladmin -uroot -p111 -S /data/3307/mysql.sock shutdown
mysqld_safe --defaults-file=/data/3307/my.cnf --read-only &
方法二:在my.cnf中[mysqld]模块下加read-only参数,然后重启数据库,配置如下
[mysqld]
read-only
Web用户专业设置方案:MySQL主从复制读写分离集群
专业的运维人员提供给开发人员的读写分离账户设置方法如下:
- 访问主库和从库使用一套用户密码,例如:用户为web,密码为111
- 即使访问IP不同,端口也尽量相同(3306)。例如:写库VIP为10.0.0.7,读库VIP10.0.0.8。
除了IP没办法修改之外,要尽量为开发人员提供方便,如果是数据库前段有DAL层(dbproxy),还可以只给开发人员一套用户、密码、IP、端口,这样就更专业了,剩下的都由鱼尾人员搞定。
下面是授权web连接用户访问的方案:MySQL主从复制读写分离集群。
方法1:从库和主库使用不同的用户,授权不同的权限
主库上对web_m用户授权
-
用户:web_m,密码:111 端口:3306 主库VIP:10.0.0.7
-
权限:select insert update delete
-
命令:
grant select,insert,update,delete on web.* to web_m@10.0.0.% identified by '111'
主库上对web_s用户授权
-
用户:web_s,密码:111 端口:3306 主库VIP:10.0.0.8
-
权限:select
-
命令:
grant select on web.* to web_m@10.0.0.% identified by '111'
提示:此方法不够专业,但是可以满足开发需求
方法2:主库和从库使用相同的用户,但授予不同的权限
主库上对web用户授权
- 用户:web密码:111 端口:3306 主库VIP:10.0.0.7
- 权限:select insert update delete
- 命令:
grant select,insert,update,delete on web.* to web_m@10.0.0.% identified by '111'
从库上对web用户授权
- 用户:web_m,密码:111 端口:3306 主库VIP:10.0.0.7
- 权限:select
- 命令:
grant select on web.* to web_m@10.0.0.% identified by '111'
提示:由于主库和从库是同步复制的,所以从库上的web用户会自动和主库一致,即无法实现只读select权限
要实现方法2中的授权方案,有两个方法
- 在主库上创建完用户和权限,从库上revoke收回对应更新权限(insert,update,delete)。
revoke insert,update,delete on `web`.* from web@10.0.0.%;
- 忽略授权库mysql同步,主库的配置参数如下:
binlog-ignore-db = mysql
replicate-ignore-db = mysql
# 参数两旁必须有空格
方法3:在从库上设置read-only参数,让从库只读
从库主库:主库和从库使用相同的用户,授予相同的权限(非ALL权限)
- 用户:web密码:111 端口:3306 主库VIP:10.0.0.7
- 权限:select insert update delete
- 命令:
grant select,insert,update,delete on web.* to web_m@10.0.0.% identified by '111'
由于主库设置了read-only,非super权限是无法写入的,因此,通过read-only参数就可以很好的控制用户非法将数据写入从库。
生产工作场景的设置方案如下:
- 忽略主库mysql同步
- 主库和从库使用相同的用户,但授权不同的权限
- 在从库上设置read-only参数,让从库只读。
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2017/05/ch6-mysql-replication/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。