本文发布于Cylon的收藏册,转载请著名原文链接~
环境配置
Ceph 是一个开源去中心化存储平台,专为满足现代存储需求而设计。 Ceph可扩展至 EB 级,并且设计为无单点故障,使其成为需要高度可用的灵活存储的应用程序的理想选择。
下图显示了具有 Ceph 存储的示例 3 节点集群的布局。 两个网络接口可用于增加带宽和冗余,这有助于保持足够的带宽来满足存储要求,而不影响客户端应用程序。
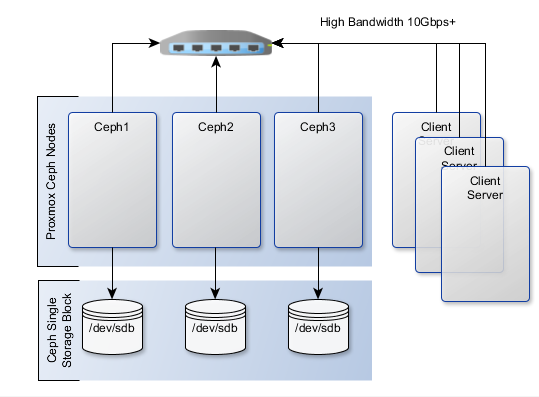
图中架构表示了一个无单点故障的 3 节点 Ceph 集群,以提供高度冗余的存储。 每个节点都配置了两个磁盘; 一台运行 Linux 操作系统,另一台将用于 Ceph 存储。 下面的输出显示了可用的存储空间,每个主机上的存储空间完全相同。 /dev/sda 是包含操作系统安装的根分区, /dev/sdb 是一个未触及的分区,将用于部署 Ceph 集群,对应的硬件信息如下表所示。
| 主机名 | public IP | cluster IP | 数据盘 |
|---|---|---|---|
| ceph-nautilus01 | 10.0.0.50 | 10.0.0.50 | /dev/sda /dev/sdb |
| ceph-nautilus02 | 10.0.0.51 | 10.0.0.51 | /dev/sda /dev/sdb |
| ceph-nautilus03 | 10.0.0.52 | 10.0.0.52 | /dev/sda /dev/sdb |
| ceph-control | 10.0.0.49 | 10.0.0.49 | /dev/sda |
部署工具
ceph-deploy 工具是在 “管理节点” (ceph-admin) 上的目录中运行。
- ceph-deploy 部署ceph的原生工具 (最后支持版本 octopus 15)
- 借助于ssh来管理目标主机,sudo,和一些 python 模块来完成 ceph 集群的部署和后期维护。
- 一般讲 ceph-deploy 放置在专用节点,作为 ceph 集群的管理节点。
- ceph-deploy 不是一个通用的部署工具,只是用于管理Ceph集群的,专门为用户快速部署并运行一个Ceph集群,这些功能和特性不依赖于其他的编排工具。
- 它无法处理客户端的配置,因此在部署客户端时就无法使用此工具。
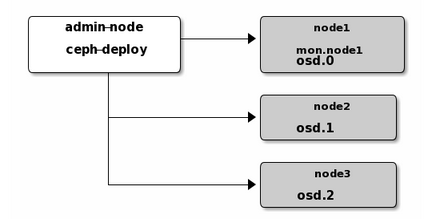
下图是来自 ceph 官网的 ceph-deploy 部署工具的一个模型图
CEPH 集群拓扑及网络
在Ceph内部存在两种流量:
- Ceph内部各节点之间用来处理OSD之间数据复制,因此为了避免正常向客户端提供服务请求,
- public network 必须,所有客户端都应位于public network
- cluster network 可选
ceph-deploy 先决条件配置
将 Ceph 安装仓库添加到 “管理节点”。然后,安装 ceph-deploy。
Debian/Ubuntu
- 添加 release key
wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
- 将 Ceph deb添加到您的存储库。并替换为安装的 Ceph 版本(例如 nautilus)。例如:
export CEPH_VERSION=nautilus
echo deb https://download.ceph.com/debian-${CEPH_VERSION}/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
- 更新仓库并安装 ceph-deploy
sudo apt update
sudo apt install ceph-deploy
RHEL/CentOS
- 安装 epel 源,这里方式很多可以任意选择 “你所在地区可用的 epel 源”
sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
- 添加 Ceph rpm 仓库
export CEPH_VERSION=nautilus
cat << EOF > /etc/yum.repos.d/ceph.repo
[ceph]
name=Ceph packages for $basearch
baseurl=https://download.ceph.com/rpm-${CEPH_VERSION}/el7/\$basearch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-${CEPH_VERSION}/el7/noarch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://download.ceph.com/rpm-${CEPH_VERSION}/el7/SRPMS
enabled=0
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
EOF
- 更新缓存并安装 ceph-deploy
sudo yum clean all && sudo yum makecache
sudo yum install ceph-deploy
安装集群的预先条件 - CEPH NODE
- 管理节点必须拥有所有 ceph node 的无密码登录权限
- ntp
- 开放端口
- 关闭 selinux
创建用于 ceph-deploy 的用户
ceph-deploy 实用程序必须以具有无密码 sudo 权限的用户身份登录 Ceph node,因为它需要在不提示输入密码的情况下安装软件和配置文件。
最新版本的 ceph-deploy 支持 –username 选项,因此您可以指定任何具有无密码的 sudo 用户(包括 root,但不推荐)。要使用 ceph-deploy –username {username},“所指定的用户必须具有对 Ceph Node 的无密码 SSH 访问权限”,因为 ceph-deploy 不会提示您输入密码。
Ceph 官方建议在集群中的所有 Ceph 节点上为 ceph-deploy 创建特定用户。==请不要使用 “ceph” 作为用户名==。整个集群中的统一用户名可能会提高易用性(不是必需的),但您应该避免使用明显的用户名,因为黑客通常会通过暴力破解来使用它们(例如 root, admin, 或使用项目名称)。以下过程将 {username} 替换为您定义的用户名,描述了如何使用无密码 sudo 创建用户。
- 在每个 Ceph Node 创建一个用户
export CEPH_USERNAME=ceph
sudo useradd -d /home/${CEPH_USERNAME} -m ${CEPH_USERNAME}
echo 1|sudo passwd ${CEPH_USERNAME} --stdin
- 对于添加到每个 Ceph Node 的新用户,请确保该用户具有 sudo 权限。
echo "${CEPH_USERNAME} ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/${CEPH_USERNAME}
sudo chmod 0440 /etc/sudoers.d/${CEPH_USERNAME}
启用 SSH 无密码登录
由于 ceph-deploy 不会提示输入密码,因此必须在管理节点上生成 SSH 密钥并将公钥分发到每个 Ceph 节点。 ceph-deploy 将尝试为初始 monitor 生成 SSH 密钥。
- 生成 ssh key,不要使用 sudo 或者是 root 用户
$ ssh-keygen
Generating public/private key pair.
Enter file in which to save the key (/ceph-admin/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /ceph-admin/.ssh/id_rsa.
Your public key has been saved in /ceph-admin/.ssh/id_rsa.pub.
- 将 SSH 密钥复制到每个 Ceph Node,将变量 “CEPH_USERNAME” 替换为创建 Ceph 部署用户创建的用户名。
通常情况下,主机名需要解析的,如果没有需要配置在 /etc/hosts 内
ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus01
ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus02
ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus03
# 如果是 root 用户执行下面命令
sudo -u ${CEPH_USERNAME} ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus01
sudo -u ${CEPH_USERNAME} ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus02
sudo -u ${CEPH_USERNAME} ssh-copy-id ${CEPH_USERNAME}@ceph-nautilus03
- 添加主机名到 /etc/hosts (可选)
$ tee >> /etc/hosts << EOF
10.0.0.50 ceph-nautilus01
10.0.0.51 ceph-nautilus02
10.0.0.52 ceph-nautilus03
EOF
网卡开机自启动
Ceph OSD Peer 并通过网络向 Ceph monitor 报告。如果默认情况下网络处于关闭状态,则在启用网络之前,Ceph 集群无法在启动期间联机。
在一些 Linux 发行版下(例如 CentOS)上的默认配置默认关闭网络接口。确保在启动过程中网络接口打开,以便 Ceph 守护进程可以通过网络进行通信。(如果你的系统是新装的)
开放所需端口
Ceph Monitor (ceph-mon) 默认使用端口 6789 进行通信。默认情况下,Ceph OSD 在 6800:7300 端口范围内进行通信。详细信息请参见网络配置参考 [1]。
确保关闭 SELinux
在 CentOS 和 RHEL 上,SELinux 默认设置为“Enforcing”。为了简化您的安装,我们建议将 SELinux 设置为 Permissive 或完全禁用,这是 Ceph 官方给出的建议
sudo setenforce 0
要持久配置 SELinux(如果 SELinux 存在问题,则建议这样做),请修改 /etc/selinux/config 中的配置文件。
Preferences
确保您的 “包管理器” 已安装并启用 “priority/preferences”。在 CentOS 上,您可能需要安装 EPEL。在 RHEL 上,您可能需要启用可选存储库。
sudo yum install yum-plugin-priorities
例如,在 RHEL 7 服务器上,执行以下命令安装 yum-plugin-priorities 并启用 rhel-7-server-optional-rpms 存储库:
sudo yum install yum-plugin-priorities --enablerepo=rhel-7-server-optional-rpms
初始化新的 CEPH 集群
在这里我们创建一个包含一个 Ceph Monitor (ceph-mon) 和 三个 Ceph OSD (osd daemon) 的 Ceph 集群。通常使用 ceph-deploy 部署集群,最佳方式是在 “管理节点” 上创建一个目录,用于维护 ceph-deploy 为集群生成的配置文件和密钥。
mkdir ceph-cluster && cd ceph-cluster
需要注意的是,ceph-deploy 将文件输出到当前目录。执行 ceph-deploy 时需要确保位于此目录中。
还需要注意的是,需要使用 “SSH 免密的那个用户”
确保集群节点清洁性
如果在任何时候遇到问题后并想重新开始,可以执行下列命令清除所有安装包和配置:
ceph-deploy purge {ceph-node} [{ceph-node}]
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
rm ceph.*
需要注意的是,执行 ceph-deploy,必须执行第四条命令 rm ceph.*
创建集群
创建集群会生成配置文件保存到当前工作目录中,使用 ceph-deploy 执行命令新建一个集群。
- 创建集群
# 语法
ceph-deploy new {initial-monitor-node(s)}
# 示例, 指定节点的 hostname, fqdn or hostname:fqdn
ceph-deploy new ceph-nautilus01 ceph-nautilus02 ceph-nautilus03
ceph-deploy 会输出到当前文件夹下的文件包含,Ceph 配置文件 (ceph.conf)、ceph-mon 的 keyring 文件 (ceph.mon.keyring) 以及新集群的日志文件。
- 如果主机存在多个网络接口(即公共网络和集群网络是分开的),需要在 Ceph 配置文件的 [global] 部分下添加公共网络设置。
public network = {ip-address}/{bits}
# 示例
public network = 10.1.2.0/24
或者通过命令指定两个网络的 IP
ceph-deploy new ceph-nautilus01 ceph-nautilus02 ceph-nautilus03 \
--cluster-network 172.18.0.0/24 \
--public-network 10.0.0.0/24
- 如果在 IPv6 环境中部署,请将以下内容添加到本地目录中的 ceph.conf 中:
echo ms bind ipv6 = true >> ceph.conf
- 现在可以安装 ceph 软件包了,执行下列命令
ceph-deploy install {ceph-node} [...]
# 示例
ceph-deploy install ceph-nautilus01 ceph-nautilus02 ceph-nautilus03
在命令执行后,ceph-deploy 将在每个节点上安装 Ceph,所以要确保对应节点需要提前安装好了 ceph yum 仓库文件
也可以通过 --release 指定版本进行安装
ceph-deploy install --release=nautilus ceph-nautilus01 ceph-nautilus02 ceph-nautilus03
- 部署 ceph-mon 并收集密钥:
ceph-deploy mon create-initial
通常完成步骤5后,本地工作目录应具有以下 keyring 文件:
ceph.client.admin.keyringceph.bootstrap-mgr.keyringceph.bootstrap-osd.keyringceph.bootstrap-mds.keyringceph.bootstrap-rgw.keyringceph.bootstrap-rbd.keyringceph.bootstrap-rbd-mirror.keyring
- 使用 ceph-deploy 将配置文件和管理密钥复制到管理节点和 Ceph Node,以便可以在这些节点上使用 ceph CLI 时而无需在每次执行命令时指定 ceph-mon 地址和 keyring文件 (ceph.client.admin.keyring)。
ceph-deploy admin {ceph-node(s)}
# 示例
ceph-deploy admin ceph-nautilus01 ceph-nautilus02 ceph-nautilus03
- 部署 CEPH MANAGER (ceph-mgr),此步骤仅需要 ==luminous+== 以上版本
ceph-deploy mgr create {ceph-node(s)} *Required only for luminous+ builds, i.e >= 12.x builds*
# 示例
ceph-deploy mgr create ceph-nautilus01
- 到步骤8时,只差 OSD 就完成了 RADOS 集群的安装,下面为集群添加 OSD
ceph-deploy osd create --data {device} {ceph-node}
# 示例
ceph-deploy osd create --data /dev/sdb ceph-nautilus01
ceph-deploy osd create --data /dev/sdb ceph-nautilus02
ceph-deploy osd create --data /dev/sdb ceph-nautilus03
Note:如果要在 LVM 卷上创建 OSD,则 –data 的参数必须是
{volume_group}/{lv_name},而不是卷的块设备的路径
- 检查集群状态
ssh node1 sudo ceph health
# or
ceph -s
Troubleshooting
No module named pkg_resources
$ ceph-deploy new ceph-nautilus01 ceph-nautilus02 ceph-nautilus03
Traceback (most recent call last):
File "/usr/bin/ceph-deploy", line 18, in <module>
from ceph_deploy.cli import main
File "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 1, in <module>
import pkg_resources
ImportError: No module named pkg_resources
解决:This issue can be solved by installing yum install -y python-setuptools.
RuntimeError: NoSectionError: No section: ‘ceph’
[2019-09-11 05:31:42,640][ceph-nautilus01][DEBUG ] Installing : ceph-release-1-1.el7.noarch 1/1
[2019-09-11 05:31:42,640][ceph-nautilus01][DEBUG ] warning: /etc/yum.repos.d/ceph.repo created as /etc/yum.repos.d/ceph.repo.rpmnew
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ] Verifying : ceph-release-1-1.el7.noarch 1/1
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ]
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ] Installed:
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ] ceph-release.noarch 0:1-1.el7
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ]
[2019-09-11 05:31:42,759][ceph-nautilus01][DEBUG ] Complete!
[2019-09-11 05:31:42,759][ceph-nautilus01][WARNING] ensuring that /etc/yum.repos.d/ceph.repo contains a high priority
[2019-09-11 05:31:42,767][ceph_deploy][ERROR ] RuntimeError: NoSectionError: No section: 'ceph'
解决:CEPH Node 上不要安装 yum 仓库,ceph-deploy 会自动安装,如果存在新的文件会被命名为 ceph.repo.rpmnew
向 RADOS 集群添加 OSD
列出并擦净磁盘
ceph-deploy disk 命令可以检查并列出OSD节点上所有可用的磁盘相关的信息。
ceph-deploy disk list stor01 stor02 stor03 stor04
如果遇到 Running command: sudo fdisk -l 无输出,原因为系统问中文,修改 en_us.utf8 后可正常显示。
$ ceph-deploy disk list stor01
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephadmin/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy disk list stor01
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fab61201488>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['stor01']
[ceph_deploy.cli][INFO ] func : <function disk at 0x7fab6144e9b0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[stor01][DEBUG ] connection detected need for sudo
[stor01][DEBUG ] connected to host: stor01
[stor01][DEBUG ] detect platform information from remote host
[stor01][DEBUG ] detect machine type
[stor01][DEBUG ] find the location of an executable
[stor01][INFO ] Running command: sudo fdisk -l
而后,在管理节点上使用 ceph-deploy 命令 擦除计划专用于OSD磁盘上的所有分区表和数据以便用于OSD,命令格式为ceph-deploy disk zab {osd-server-name} {disk-name},需要注意的是此步会清除目标设备上的所有数据。
擦除一个磁盘
ceph-deploy disk zap
ceph-deploy disk zap {ceph_node} /dev/sdb
Note:如果是未格式化的块设备不需要额外擦除,ceph 集群要求 ceph 管理的块设备必须是未格式化的,如果格式化过的需要擦除
ceph-deploy osd –help:
block-db可以理解为RocksDB数据库,元数据存放的位置block-wal数据库的数据日志存放的位置filestore如果使用filestore,明确指定选项--filestore指明数据放哪,并指明日志放哪(日志指的是文件系统日志)ceph-deploy osd create {node} --filestore --data /path/to/data --journal /path/to/journal- bluestore自身没有文件系统,故无需日志,数据库需要日志
扩展集群
添加 OSD
当一个 “基本集群” 部署好并运行,下一步就是扩展集群。通常会扩展集群,扩展集群存在两种类型,集群组件与OSD,这里主要围绕 扩展 OSD
早期版本的ceph-deploy命令支持在将添加OSD的过程分为两个步骤:准备OSD,激活OSD,但新版本中,此种操作方式已被废除,添加OSD的步骤只能由命令 ceph-deploy osd create create {node} –data {data-disk} ,一次完成,默认存储引擎为 bluestore
ceph-deploy osd create {node} --data /dev/sdb
ceph-deploy osd create {node} --data /dev/sdc
而后可使用 ceph-deploy osd list {node} 命令列出指定节点上的OSD:
移除 OSD 的
Ceph集群中的一个OSD通常对应一个设备,且运行于专用的守护进程。在某OSD设备出现故障,或管理员出于管理只需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。对于Luminous及其之后的版本来说,停止和移除命令的格式如下
- 停止设备: ceph osd out {osd-num}
- 停止进程: sudo systemctl stop ceph-osd@{osd-num}
- 移除设备: ceph osd purge {id} –yes-i-really-mean-it
若类似如下的OSD的设备信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除。
[osd.1]
host = {hostname}
不过,对于 Luminous 之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备
- 于CRUSH运行图中移除设备: ceph osd crush remove {name}
- 移除OSD的认证key: ceph auth del osd.{osd-num}
- 移除设备: ceph osd purge {id} –yes-i-really-mean-it
扩展 ceph-mon
Ceph 集群需要至少一个 Ceph Monitor 和一个 Ceph Manager,生产环境中,为了实现高可用,Ceph集群通常运行多个监视器,以免单监视器整个存储集群崩溃。Ceph使用 Paxos 算法,改算法是需要至少需要板书以上的监视器(大于n/2,其中n为总监视器数量),才能形成法定人数,尽管此非必须,奇数个 ceph-mon 往往更好。
使用 ceph-deploy mon add {nodes} 命令可以一次添加一个 ceph-mon 到集群中。
ceph-deploy mon add nautilus02 ## 此处使用短格式名称,长格式名称会报错。
ceph-deploy mon add nautilus03
设置完成后,可以在ceph客户端上查看监视器及法定人数的相关信息:
$ ceph quorum_status --format json-pretty
{
"election_epoch": 20,
"quorum": [
0,
1,
2
],
"quorum_names": [
"stor01",
"stor02",
"stor03"
],
"quorum_leader_name": "stor01",
"monmap": {
"epoch": 3,
"fsid": "69fb9b55-3fb5-42d0-8cf7-239a3b569791",
"modified": "2019-06-06 21:19:41.274199",
"created": "2019-06-05 12:35:31.143594",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "stor01",
"addr": "10.0.0.4:6789/0",
"public_addr": "10.0.0.4:6789/0"
},
{
"rank": 1,
"name": "stor02",
"addr": "10.0.0.5:6789/0",
"public_addr": "10.0.0.5:6789/0"
},
{
"rank": 2,
"name": "stor03",
"addr": "10.0.0.6:6789/0",
"public_addr": "10.0.0.6:6789/0"
}
]
}
}
扩展 Manager 节点
Ceph Manager (ceph-mgr) 以 Active/Standy 模式运行,部署其他 ceph-mgr 守护进程可确保在 Active 节点的 ceph-mgr 守护进程故障时,其中一个 Standby 实例可以在不中断服务的情况下接管其任务。
mgr 就是无状态的 web 服务,一般来讲两个足够了。
ceph-deploy mgr create {ceph_node}
启动 RGW
RGW (Rados Gateway) 必要组件,仅在需要用到对象存储兼容 “S3” 和 “Swift” 的 RESTful 接口时才需要部署 RGW 实例,相关的命令为ceph-deploy rgw create (gateway-node) 。
radosgw需要用自用的存储池不能与RBD混合使用,RGW 会在创建时自动初始化出存储池来,RGW 需要有相应服务才能运行起来。
ceph-deploy rgw create nautilus02
添加完成后,ceph -s 命令的 service 一段中会输出相关信息:
$ ceph -s
cluster:
id: 69fb9b55-3fb5-42d0-8cf7-239a3b569791
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum stor01,stor02,stor03
mgr: stor01(active), standbys: stor04
osd: 8 osds: 8 up, 8 in
rgw: 1 daemon active
data:
pools: 7 pools, 160 pgs
objects: 196 objects, 1.5 KiB
usage: 21 GiB used, 79 GiB / 100 GiB avail
pgs: 160 active+clean
默认情况下,RGW 实例监听于 TCP 协议的 7480 端口,需要修改,可以通过在运行 RGW 的节点上编辑其主配置文件 ceph.conf 进行修改,相关参数如下所示
[client]
rgw_frontends = "civetweb port=8080"
RGW 会在 RADOWS 集群上生成包括如下存储池的一系列存储池
$ ceph osd pool ls
mypool
rbdpool
testpool
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
RGW 提供的是兼容 S3 和 Swift 的 REST 接口,客户端通过 HTTP 进行交互,完成数据的增删改查等管理操作。
启用文件系统 (CephFS) 接口
CephFS 需要至少运行一个 Metadata (MDS) 守护进程 (ceph-mds),此进程管理与 CephFS 上存储的文件相关的元数据,并协调对 Ceph存储集群的访问。因此,若要使用 CephFS ,需要在存储集群中至少部署一个 MDS 实例,增加 MDS 可以使用命令 ceph-deploy mds create {ceph-node} 完成
还需主义的是,每个 CephFS 都至少需要两个存储池,一个用来存放元数据 (Metadata Pool),一个存放数据 (Data Pool)。
$ ceph-deploy mds create stor01
查看 MDS 的相关状态可以发现,刚添加的 MDS 处于 standby 状态
在运行起来还不够,还没为其创建存储池,故其不能正常工作,处于standby模式。
$ ceph mds stat
, 1 up:standby
使用 CephFS 之前需要事先于集群中创建一个文件系统,并为其分别指定 “元数据” 和 “数据” 相关的存储池,下面创建一个名为 cephfs 的文件系统用于测试,使用cephfs-metadata为数据存储池,使用cephfs-data为数据存储池。
# 创建存储池
ceph osd pool create cephfs-metadata 64
ceph osd pool create cephfs-data 64
# 创建 cephfs
## 语法
ceph fs new {fs_name} {meatadata-pool} {data-pool}
## 示例
ceph fs new cephfs cephfs-metadata cephfs-data
- ceph fs add_data_pool: 额外添加数据池
- ceph fs new: 创建新文件系统
- ceph fs status: 查看CephFS 文件系统状态
$ ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+--------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+--------+---------------+-------+-------+
| 0 | active | stor02 | Reqs: 0 /s | 10 | 13 |
+------+--------+--------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 2286 | 21.7G |
| cephfs-data | data | 0 | 21.7G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
+-------------+
MDS version: ceph version 13.2.6 (7b695f835b03642f85998b2ae7b6dd093d9fbce4) mimic (stable)
Reference
[1] Network Configuration Reference
[2] ceph_deploy RuntimeError: NoSectionError: No section: ‘ceph’
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2019/11/02-2-install-ceph-with-ceph-deploy/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。