本文发布于Cylon的收藏册,转载请著名原文链接~
Prometheus的四种数据类型
- Counter(计数器类型) Counter类型的指标的工作方式和计数器一样,只增不减
- Gauge(仪表盘类型) Gauge是可增可减的指标类,通常用于反应当前应用的状态。
- Histogram 主要用于表示一段时间范围内对数据进行采样
- Summary(摘要类型) Summary类型和Histogram类型相似,主要用于表示一段时间内数据采样结果
Prometheus 的局限
- Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
- Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos等方案。
- 监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说Thanos 去重的时候会提到。
- Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方
采集组件 All IN One
Prometheus 体系中 Exporter 都是独立的,每个组件各司其职,如机器资源用 Node-Exporter,Gpu 有Nvidia Exporter等等。但是 Exporter 越多,运维压力越大,尤其是对 Agent做资源控制、版本升级。我们尝试对一些Exporter进行组合,方案有二:
- 通过主进程拉起N个 Exporter 进程,仍然可以跟着社区版本做更新、bug fix。
- 用Telegraf来支持各种类型的 Input,N 合 1。另外,Node-Exporter 不支持进程监控,可以加一个Process-Exporter,也可以用上边提到的Telegraf,使用 procstat 的 input来采集进程指标。
合理选择黄金指标
采集的指标有很多,我们应该关注哪些?Google 在 “Sre Handbook” 中提出了“四个黄金信号”:延迟、流量、错误数、饱和度。实际操作中可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
- Use 方法:Utilization、Saturation、Errors。如 Cadvisor 数据
- Red 方法:Rate、Errors、Duration。如 Apiserver 性能指标
Prometheus 采集中常见的服务分三种:
- 在线服务:如 Web 服务、数据库等,一般关心请求速率,延迟和错误率即 RED 方法
- 离线服务:如日志处理、消息队列等,一般关注队列数量、进行中的数量,处理速度以及发生的错误即 Use 方法
- 批处理任务:和离线任务很像,但是离线任务是长期运行的,批处理任务是按计划运行的,如持续集成就是批处理任务,对应 K8S 中的 job 或 cronjob, 一般关注所花的时间、错误数等,因为运行周期短,很可能还没采集到就运行结束了,所以一般使用 Pushgateway,改拉为推。
如何采集 LB 后面的 RS 的 Metric
假如你有一个负载均衡 LB,但网络上 Prometheus 只能访问到 LB 本身,访问不到后面的 RS,应该如何采集 RS 暴露的 Metric?
- RS 的服务加 Sidecar Proxy,或者本机增加 Proxy 组件,保证 Prometheus 能访问到。
- LB 增加 /backend1 和 /backend2请求转发到两个单独的后端,再由 Prometheus 访问 LB 采集。
Prometheus 大内存问题
随着规模变大,Prometheus 需要的 CPU 和内存都会升高,内存一般先达到瓶颈,这个时候要么加内存,要么集群分片减少单机指标。这里我们先讨论单机版 Prometheus 的内存问题。
原因:
- Prometheus 的内存消耗主要是因为每隔2小时做一个 Block 数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关。
- 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间。
- 一些不合理的查询条件也会加大内存,如 Group 或大范围 Rate。
我的指标需要多少内存:作者给了一个计算器,设置指标量、采集间隔之类的,计算Prometheus 需要的理论内存值:计算公式
以我们的一个 Prometheus Server为例,本地只保留 2 小时数据,95 万 Series,大概占用的内存如下:
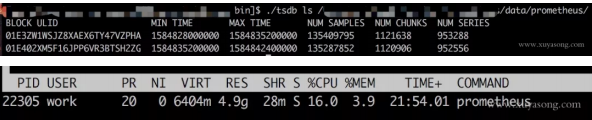
有什么优化方案:
- Sample 数量超过了 200 万,就不要单实例了,做下分片,然后通过 Victoriametrics,Thanos, Trickster 等方案合并数据。
- 评估哪些 Metric 和 Label 占用较多,去掉没用的指标。2.14 以上可以看 Tsdb 状态
- 查询时尽量避免大范围查询,注意时间范围和 Step 的比例,慎用 Group。
- 如果需要关联查询,先想想能不能通过 Relabel 的方式给原始数据多加个 Label,一条Sql 能查出 来的何必用Join,时序数据库不是关系数据库。
Prometheus 内存占用分析:
- 通过 pprof分析
- 1.X 版本的内存
- 相关 issue:
Prometheus 容量规划
容量规划除了上边说的内存,还有磁盘存储规划,这和你的 Prometheus 的架构方案有关。
- 如果是单机Prometheus,计算本地磁盘使用量。
- 如果是 Remote-Write,和已有的 Tsdb 共用即可。
- 如果是 Thanos 方案,本地磁盘可以忽略(2H),计算对象
Prometheus 每2小时将已缓冲在内存中的数据压缩到磁盘上的块中。包括Chunks、Indexes、Tombstones、Metadata,这些占用了一部分存储空间。一般情况下,Prometheus中存储的每一个样本大概占用1-2字节大小(1.7Byte)。可以通过Promql来查看每个样本平均占用多少空间:
如果大致估算本地磁盘大小,可以通过以下公式:$磁盘大小=保留时间每秒获取样本数样本大小$
保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁 盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
查看当前每秒获取的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。考虑到 Prometheus 会对时间 序列进行压缩,因此减少时间序列的数量效果更明显。
举例说明:
- 采集频率 30s,机器数量1000,Metric种类6000,1000600026024 约 200 亿,30G 左右磁盘。
- 只采集需要的指标,如 match[], 或者统计下最常使用的指标,性能最差的指标。
以上磁盘容量并没有把 wal 文件算进去,wal 文件(Raw Data)在 Prometheus 官方文档中说明至少会保存3个 Write-Ahead Log Files,每一个最大为128M(实际运行发现数量会更多)。
因为我们使用了 Thanos 的方案,所以本地磁盘只保留2H 热数据。Wal 每2小时生成一份Block文件,Block文件每2小时上传对象存储,本地磁盘基本没有压力。
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2021/10/interview-monitor/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。