本文发布于Cylon的收藏册,转载请著名原文链接~
overview
Q1: 为什么需要非连续内存分配
连续内存管理 (contiguous memory allocation), 即 : 操作系统加载到内存以及程序加载到内存中时, 分配一块连续的内存块. 但这种方式会出现碎片问题,而非连续内存分配(Non-contiguous memory allocation )可以有效的减少碎片(Fragmentation)的出现。
Q2: 主要的非连续内存分配的管理方法
- 分段(
Segmentation) - 分页(
Paging) - 页表 (
Page Table)
1.非连续内存分配的必要性
连续内存管理的缺陷:
- 内存利用率较低(
memory wastage),在程序运行时分配的内存是增长的,但在进程使用为达到分配大小时,分配的块并未使用,并且也不能给其他进程使用,造成了内存的浪费。 - 分配给一个程序的物理内存必须是连续的。
- 碎片化问题
- 不灵活(
inflexibility),当进程或文件使用的内存超出预期时(即:超出分配的内存块大小),将停止并抛出异常,例如:No disk space。
非连续内存分配的优点:
- 一个程序的物理地址空间是非连续的
- 更好的内存利用和管理,(减少了内存浪费)
- 允许共享代码与数据(共享库等…)
- 支持动态加载和动态链接
非连续内存分配的缺点:
- 建立虚拟地址和物理地址的转换难度大
- 软件方案
- 硬件方案(采用硬件方案) : 分段 / 分页
分段(segmentation)
首先 segmentation mechanism需要考虑的问题:
- 程序的分段地址空间
- 分段寻址方案
什么是segmentation
段(segmentation)是一个逻辑单元 (logical unit),例如:
- 主程序
main program - 程序(主要是指功能的代码,如一段函数)
procedure - 函数
function - 方法
method - 对象
object - 局部变量和全局变量
local variables,global variables - 公共块
common block - 堆
stack - 符号表
symbol table - 数组
arrays
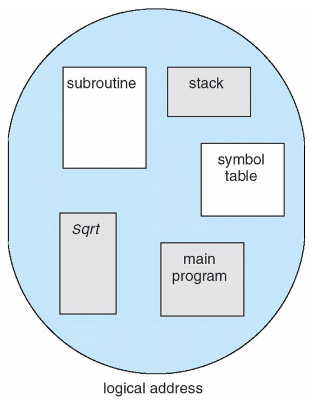
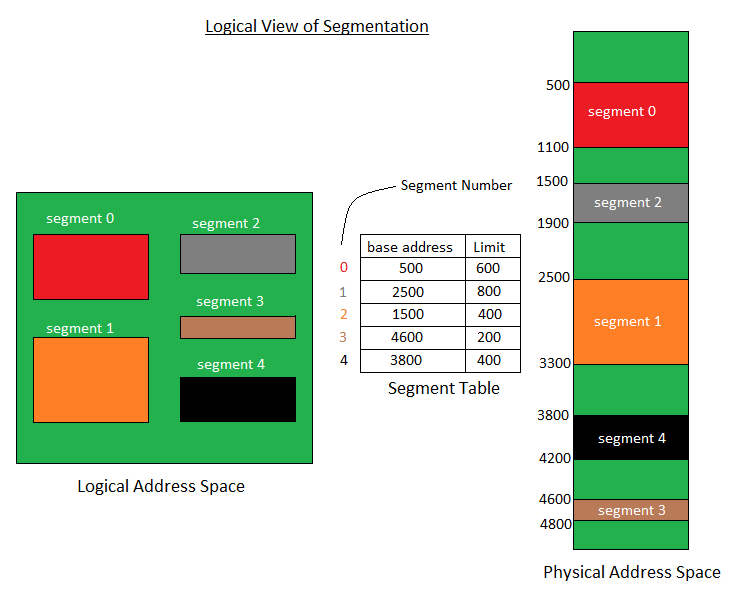
可以看到左边是逻辑地址,右边是不连续的物理地址,中间有一个映射机制将两边建立了一个关联关系(ST Segment Table)。通过映射机制将不同的块(如stack,function..)分别映射到内存中的段中。
分段寻址方案
一维逻辑地址与分段的物理地址对应的方法,分段寻址 (Segmentation Addressing modes),逻辑地址由两部分组成,segment number (==s==) 和 offset (==d==)。
- s 表示段所需的总位数
- d 指定了段大小所需的位数
基于硬件的分段管理机制 Segmention hardware
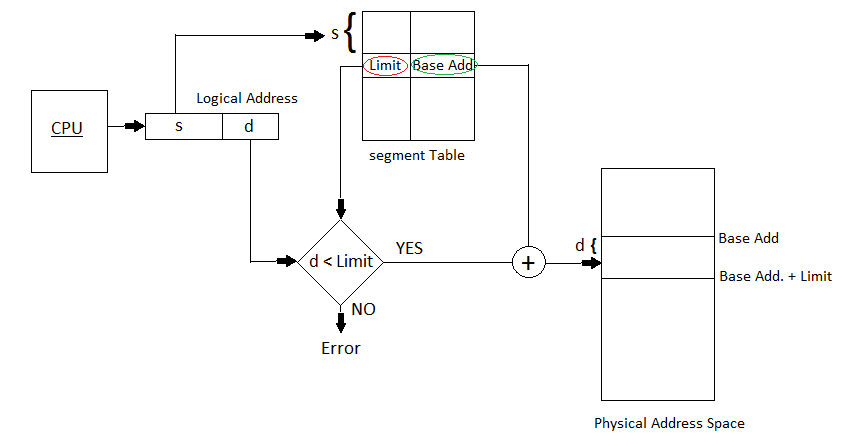
程序表示为了一个二维地址,但在实际物理内存中是一个一维地址。因此需要将二位地址 ( two-dimensional)映射为一个一维物理地址 (one-dimensional),这个机制就是段表 (Segment Table),ST映射了逻辑地址的段号和物理地址的段号。并且段的长度与起始信息也是存放在ST中的。
段表(ST)中的每个条目都有一个base和一个段 limit。==base== 包含段所在在内存中的起始物理地址,而==limit==指定段的长度。
如图所示,逻辑地址由两部分组成:s和d。s 作为 ST 的 index 。d必须在0和 limit 之间。当超出limit范围是,CPU会产生异常。当 d 合法时,将其添加到 base 以生成地址物理地址。
起始物理地址 = d + base
结束物理地址 = base + limit
分页(Paging)
overview
本章主要分为两部分:
- 分页地址空间
- 页寻址方式
分页 (Paging) 与 分段 (Segmentation) 都是非连续性内存管理的机制,分段允许进程的物理地址空间不连续;而分页则是比分段较有优势的另一种内存管理方案。
分页的特点:
- 将每个块划分为固定的页。
- 划分物理内存为固定大小(
fixed-sized) 的块 (block) 称作帧 (frame)- 大小是2的幂, e.g. 512 / 4096 / 8192
- 逻辑地址相同大小的的块 (
blocks) 称作 (Pages)- 大小是2的幂, e.g. 512 / 4096 / 8192
- 划分物理内存为固定大小(
- 每个段需要一个页表。
- CPU的内存管理单元需要同时支持 分页和分段。
帧 Frame
物理地址 (Physical Address)空间在划分为若干固定大小的块,称为帧。帧由两部分组成,Frame number(f) 和 Frame offset(==d==)
- Frame number(f): 表示物理地址空间的帧所需的位数。
- Frame offset(d): 表示页中物理地址空间的页大小或页或页偏移量的字数所需的位数。
如图所示,物理地址是一个二元组 $(f,d)$,页帧占 $F$ 位,共有 $2^F$ 帧;偏移量 o 占了 $S$ 位(一个帧的大小),共$2^S$ 字节 ,则物理地址 = $2^S\times f+d$ 。
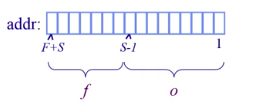
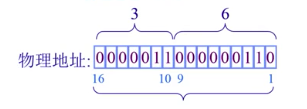
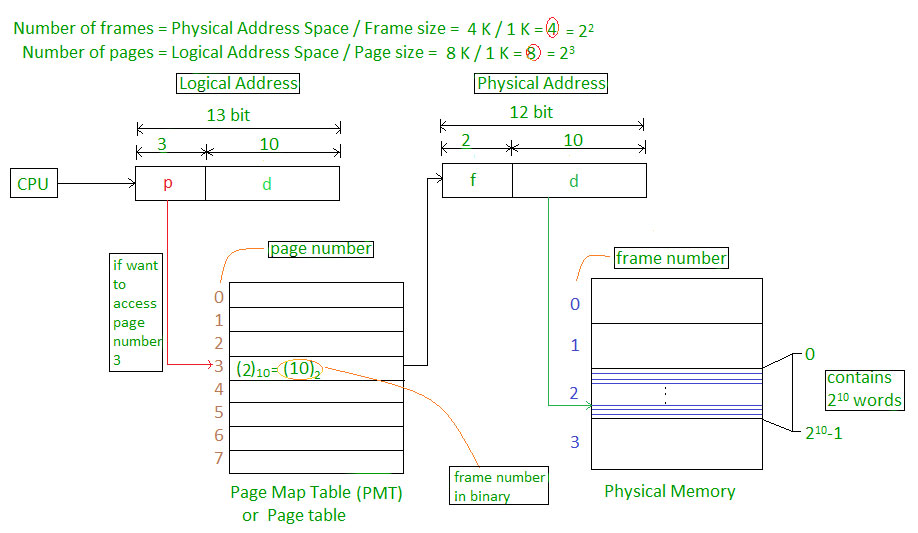
地址计算:16bit的物理地址空间,页帧大小为9bit(512byte)
- 给出物理地址$(f,d) = (3,6)$,求物理地址的位置 。
- $S=9$,$F=7$, $f=3$ ,$d=6$
- 套用公式得出,$2^9\times3+6 = 1542$
页 Page
逻辑地址相同大小的的块 (blocks) 称作 (Pages),
- 页的偏移的大小=帧内偏移的大小
- 页号 <> 帧号大小
Page也有两部分组成,页号和页的偏移。Page number(==p==) 和 Page offset(==d==);
- Page number(p) 逻辑地址空间中页所需的位数
- Page offset(d):逻辑地址空间中页偏移量的字数所需的位数。
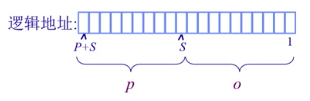
如图所示,一个逻辑地址表示为一个二元组 $(p,d)$,页帧占 $P$ 位,共有 $2^P$ 帧;偏移量 o 占了 $S$ 位 (一个页的大小),共$2^S$ 字节 ,则物理地址 = $2^S\times p+d$ 。
页的寻址机制
在图中可以看出,逻辑地址是一个连续的地址空间,并且由一个个Page组成,首先CPU寻址,地址分位两块(一个二元组)$(p,d)$,p作为一个index 去查一个page table (以页号为索引的值为帧号) ,以index与base(基地址)作为查找项查找对应的f,$f + (f)d$ 就找到了对应的物理地址。
- 页映射到帧
- 页是连续的虚拟内存
- 帧是非连续的物理内存
- 不是所有的页都有对应的帧
页表
overview
页表(page table)结构:页表虚拟内存统用来存储逻辑地址 (Virtual Address) 到物理地址 ( Physical Address ) 映射关系的一种数据结构。
页表的特性:
- 在页表中,每个映射被称为页表项(
Page Table Entries (PTEs))这个页表项负责逻辑地址到物理地址的转换。 - 该表存储在页表基址寄存器(
PTBR,``Page-table base register`) - 随进程运行状态而动态变化。
页表项(PTE) 的组成:
-
物理页号(
Physical Page NumberPPN) -
DPN(
disk page number)的磁盘上的页面 -
帧号
-
标记位
- 脏位/修改位(
Dirty Bit(D)):每个PTE都包含的一个修改位,表示页面自加载后是否已写入。是在操作系统中完成,而不是在硬件中完成的操作。- 1:表示数据是"脏的(
dirty)",即已写入。 - 0:数据是“干净的(
clean)”,与加载时相同。
- 1:表示数据是"脏的(
- 存在位/驻留位 (
resident bit(R)):每个PTE都包含的一个驻留位,表示逻辑地址是否有一个物理地址与其相对应。- 1:当逻辑页在物理内存中时,该位被设置为1。
- 0:如果为0,则访问该虚拟页面将导致页面错误。
- 引用位 (
Eviction Bit,In x86:Reference Bit),过去一段时间内是否有对其引用(是否访问过页内的某个存储单元)。存在页表的第二位,在每次访问页面时(读/写),Reference Bit设置为1。- 1:最近被引用过。
- 0:从未被引用。
- Read/Write Bit
- NX Bit
- 脏位/修改位(
页表的转换 (translation process)
CPU的内存单元(MMU, memory management unit)根据程序的page的页号的若干位, 计算出索引值index, 在页表中搜索这个index, 得到的是帧号, 帧号和原本的offset组成物理地址.
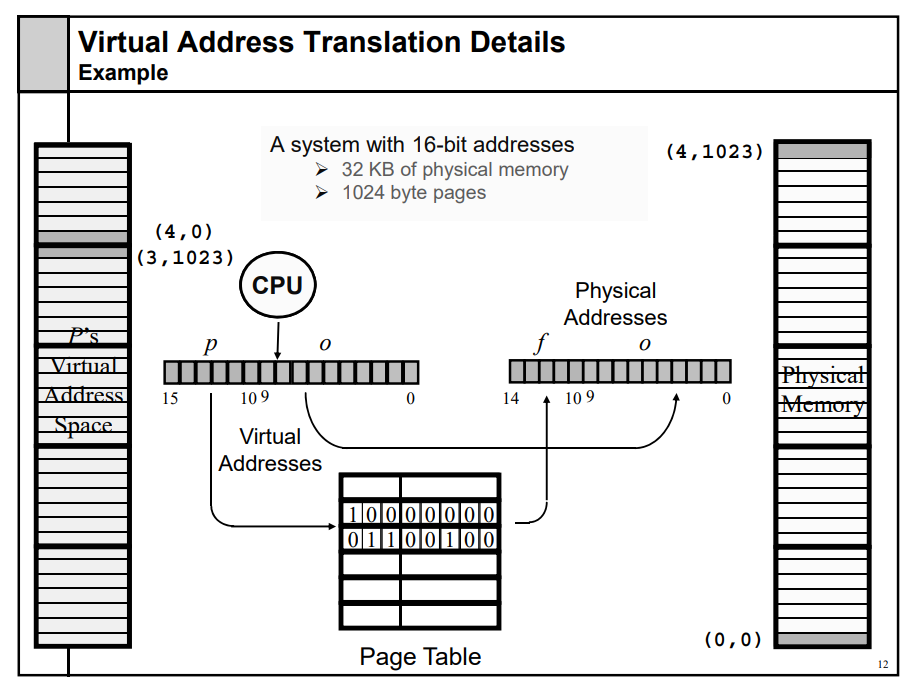
Quick Activity
具有16位地址的计算机系统,物理地址大小32KB,每页大小1024bites,的逻辑地址如何进行转换。
16位地址是0~15,0~9是页内偏移
d, 10~15是页号。
页式存储管理机制存在的问题
- 内存访问性能问题(
Performance Issues):内存访问性能,虚拟地址访问需要2次内存访问- 第一次获取页表项
- 第二次访问数据
- 页表大小问题:页表可以非常大。
- 页表可能很大
- 如图实例,32K内存,每页1K,即32个页表项,如果每项占4byte,则为128byte。
- 对于具有64位地址和1024字节页的机器,页表的大小是多少?
- 页:$2^{64}$,页的大小:$2^{10}$,需要建立页表的大小:$2^{64} \div 2^{10} = 2^{54}$
- 页表可能很大
如何解决上述问题(what to do):
- Caching 缓存,solution:快表,利用缓存机制减少对页表的访问。
- Indirection 间接访问,solution:多级页表,通过间接引用的方式来减少页表的长度。
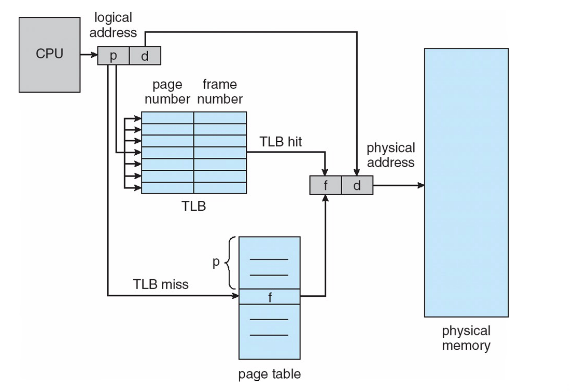
快表 translation look-aside buffers (TLBs)
对于上述的性能问题,有效的解决方法是对页表项(PTE)的高速缓存,成为快表(translation look-aside buffer (TLB))。快表就是将近期访问过的页表项在CPU内部使用硬件缓存,即将近期访问过的项缓存到CPU中;TLB由内存管理单元(MMU)管理
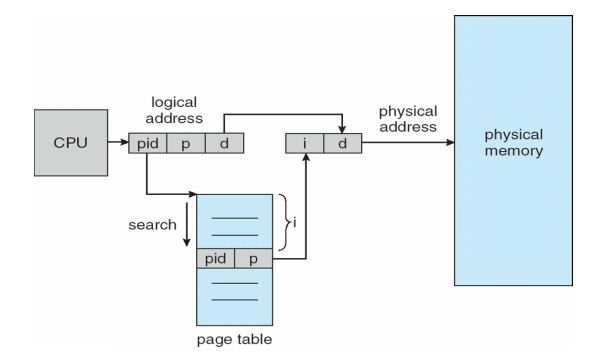
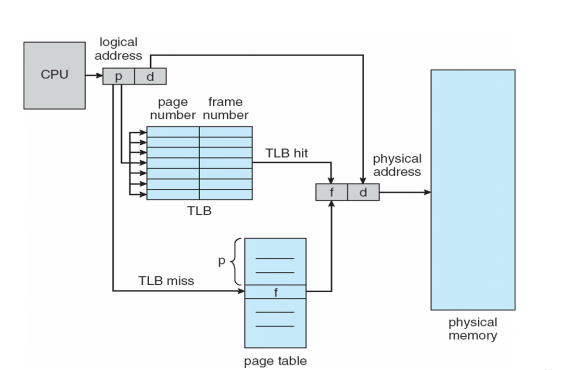
如图所示,如果TLB命中,则直接可以获取到物理地址,如果TLS未命中,则同时将内容缓存到CPU中的TLB。
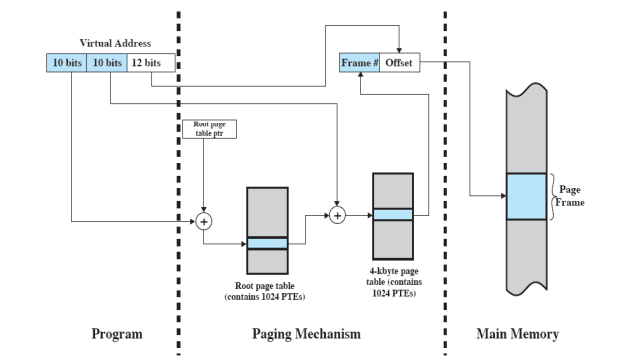
多级页表
多级页表是通过间接引用的方式将页号分成多级。多级页表是树状结构,用于保存页表。
例子,考虑两个级别的页表再次在具有$2^{12}=4$ KB Page 的32-bit架上,
Q1:第二级页面表格有多少位?
- $4KB\div4B = 1024=2^{10}$
Q2:顶级页表有多少位?
- $32-12-10=10$
10bits 表示0级索引,10bits表示1级索引,12bits表示页面内的偏移量。每一个子页表的开头作为上一个页表的页号物理页号填写到上一级页表当中。
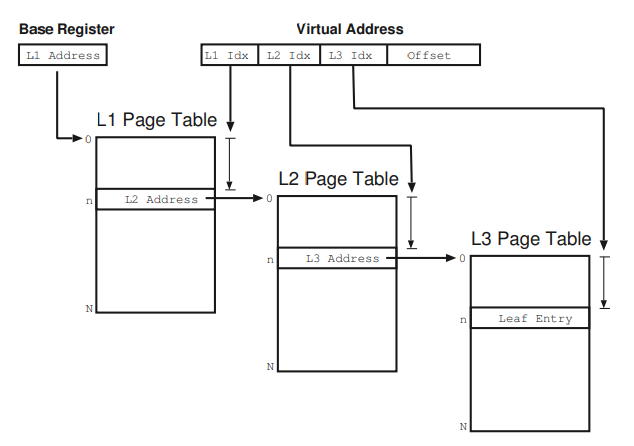
多级页表计算题
一个32位操作系统中进程的虚拟地址空间可达到4GB,假设用户地址空间为2GB,页面大小为4KB,
Q1:则一个进程最多可以有()页。
- $2G = 2\times 2^{10} \times 2^{10} \times 2^{10} = 2^{31} $
- $4KB = 2^2 \times 2^{10} = 2^{12}$
- 即 $2^{31}\div2^{12} = 2^{19}$
Q2:若用4个字节表示一页的物理页号,则页表本身就占用()?
- $4B\times 2^{19} = 2^2 \times 2^{19} = 2^{21} = 2M $
Q3:即需要()个页面存放。
- $2M\div4KB = 2^{21}\div2^{12} = 2^{9} = 512$
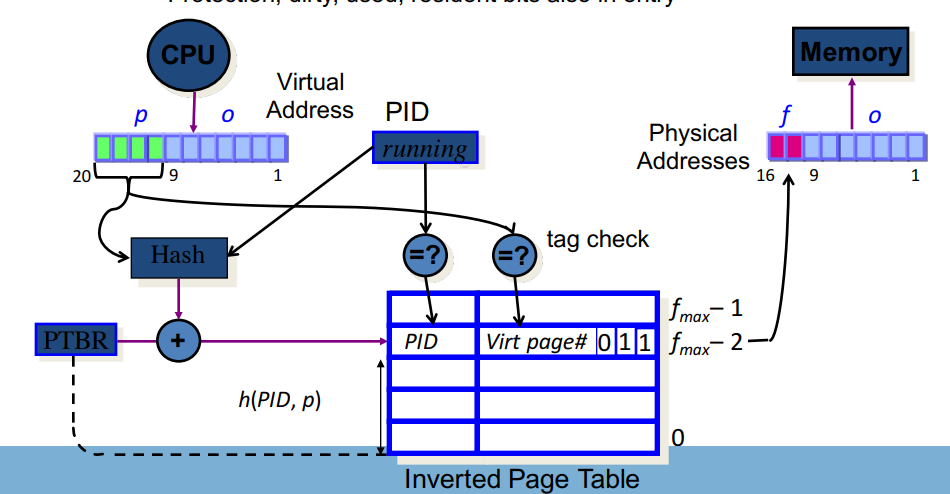
反置页表
使用页寄存器(Page Registers),又名反置页表(Inverted page table (IPT)),是为了减少所占用存储空间的一种做法。使用反置页表的原因是在大地址空间(64-bits)的系统上,多级页表会变得繁琐,例如,逻辑地址空间增长速度快于物理空间地址。(以页帧号为索引,页表号为内容 )
此时产生一个问题:如何查找?(frame number是索引,pagenumber是内容)。基于关联存储器(associative memory)的方案:
关联存储器也可以并行的查找,与寄存器可以同时比较,如果找到匹配值,则输出与键对应的值。
- 如果帧数较少,页寄存器可以被放置在关联内存中
- 在关联内存中查找逻辑页号
关联存储器的代价:
如果帧数较少,页寄存器可以被放置在关联内存中;在关联内存中查找逻辑页号:
- 成功,则拿到帧号
- 失败,也错误异常(
page fault)
限制因素:很难在单个时钟周期完成;耗电。
IPT的具体思路为,不让页表与逻辑地址空间的大小对应,而是让页表与物理地址空间大小相对应,每个帧都与一个寄存器相关联,通常该寄存器包含:
- 引用位(
Residence bit):标记该帧(Frame) 是否被进程占用。 - 占用页号(
Occupier):页帧对应的页号 - 保护位(
Protection bits):约定页的访问方式(R/W)
Quick Activity
系统有
- 物理内存大小:16MB( $4096 \times 4096 = 4K \times 4K = 16MB $ )
- 页大小为:4KB( $4096bytes = 4KB $)
- 页帧数为4K(4096)。
- 假定每一个页寄存器(
page resigter)占8bytes, $4096 \times 8 = 32Kbytes$。那么页寄存器占用的开销为: $32Kb\div 16Mb \approx 0.2%$。此时和虚拟地址没有关联了。创建的进程的物理地址就与页寄存器对应。
页寄存器方案的优缺点:
- 优点:
- 页表大小相对于物理内存而言很小
- 页表大小与逻辑(虚拟)地址无关
- 缺点:
- 页表信息对调后,需要帧号可以找到页号
- 在页寄存器中搜索逻辑地址中的页号
基于hash计算的反向页表 hash table
hash table,一个数学计算的方法。通过hash计算输入为page number,输出为 frame number。由图所示
- Virtual Page Number (VPN):
p,q - Page Frame Number (PFN):
r - Offset:
d - Hash Function:
h(x) - Hashed Page Table with schema
(key, VPN, PFN, Pointer to next entry with key)每一个页表项
hash table方式的工作流
-
操作系统从CPU拿到 虚拟内存
p,并执行h(p)以获取 same_key。 -
操作系统查找哈希页表中的第一个条目,其中 key = same_key,并根据第一个页表的 虚拟内存页号
p。(根据第一个项中的指针来查找第二个项。它知道第二个项具有相同的键 = same_key,因为多级页表工作流是如此。操作系统根据第二项的页表号字段检查p。 -
操作系统从第二个条目中获取帧号
r。r对应于虚拟页号p的正确物理帧号;操作系统使用 页帧r+ 偏移量d在物理内存中查找它想要的物理地址。
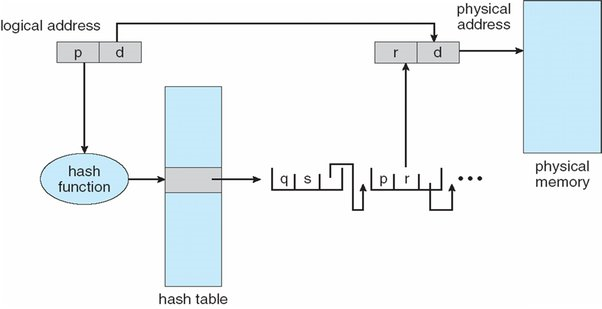
由图可以看出,为了提高效率,可以对hash函数增加一个参数 pid ,可以作为输入,来设计一个hash函数,算出对应的frame number。这种可以很好的解决映射的开销。
段页式存储管理
段页式存储管理机制 ( Segmented Paging ),是从页式与段式两种技术中获得最佳特性,纯分段不是很流行,并且在许多操作系统中都没有使用。但是,分段可以与分页相结合。段式存储在内存保护方面有优势,页式存储在内存利用和转移到后备存储方面有优势。
段页式存储管理机制是在段式存储的基础上给每一个段加一级页表。即,主存被划分为可变大小的段,这些段又被进一步划分为固定大小的页,此时就有三个定义词Definitions
- 段号 **Segment Number **
- 页号 **Page Number **
- 页偏移 **Page Offset **
如图所示,通过为每个段创建页表,可以减小页表的大小(要实现这一点,需要硬件支持),CPU提供的地址现在将被划分为段号、页号和偏移量。

段页式存储机制工作流如图所示:
CPU生成一个逻辑地址分为两部分:段号和段偏移量。段偏移必须小于段限制。偏移量又分为页码和页偏移。要映射页表中的确切页码,请将页码添加到页表库中。带有页帧号+页偏移组成了实际被映射的物理地址。
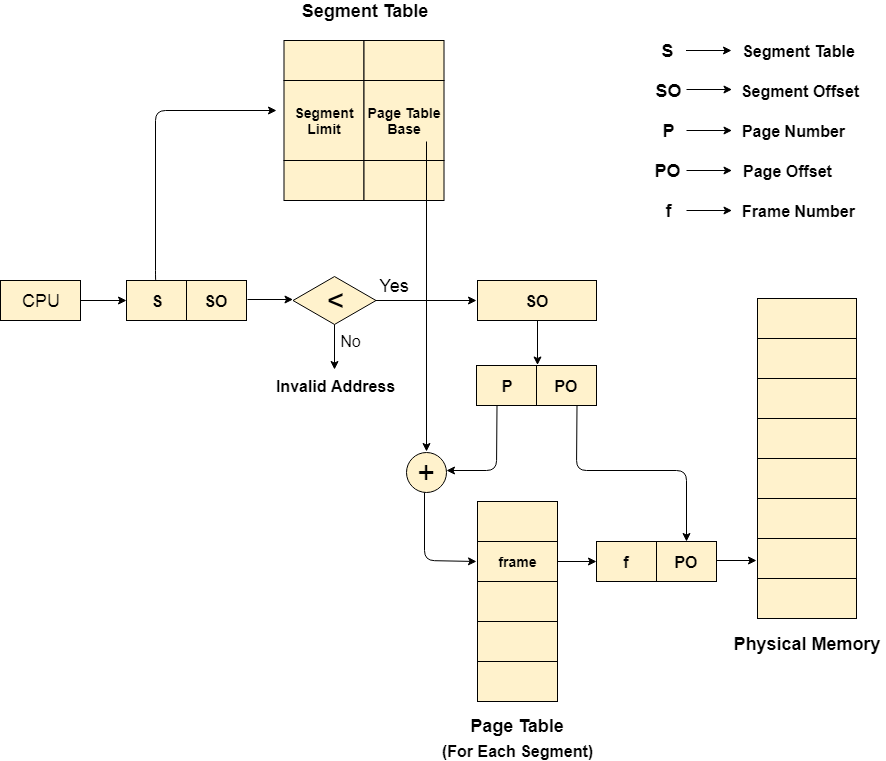
通过只想相同的页表基址,时间进程间的段共享
https://www.cs.utexas.edu/users/witchel/372/lectures/15.VirtualMemory.pdf
https://www.pvpsiddhartha.ac.in/dep_it/lecture%20notes/OS/unit4.pdf
https://www.studytonight.com/operating-system/difference-between-paging-and-segmentation
https://www.utc.edu/sites/default/files/2021-04/2800-lecture8-memeory-management.pdf
https://www.geeksforgeeks.org/paging-in-operating-system/?ref=lbp
https://cw.fel.cvut.cz/old/_media/courses/ae3b33osd/osd-lec6-14.pdf https://www.inf.ed.ac.uk/teaching/courses/os/slides/10-paging16.pdf
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2022/04/ch4-non-contiguous-memory-allocation/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。