本文发布于Cylon的收藏册,转载请著名原文链接~
Overview
文件系统和文件
文件系统: 一种用于持久性存储的系统抽象,决定了辅存中的内容如何组织与存储的抽象概念
文件:文件系统中的一个单元的相关数据在操作系统中的抽象,展现给用户的抽象概念
文件系统的功能:
- 分配文件磁盘空间
- 管理文件块(哪一块属于哪一个文件)
- 管理空闲空间(哪一块是空闲的)
- 分配算法(策略)
- 管理文件集合
- 定位文件及其内容
- 命名:通过名字找到文件的接口
- 最常见:分层文件系统
- 文件系统类型(组织文件的不同方式)
- 提供的便利及特征
- 保护:分层来保护数据安全
- 可靠性,持久性:保持文件的持久即使发生崩溃,媒体错误,攻击等
为什么需要文件系统:
如果将文件放入一个房间中,整个房间都是堆积的文件

有了文件系统的存在将会改变一切

空间管理、元数据、数据加密、文件访问控制和数据完整性等等都是文件系统的职责。
文件属性
文件具有名称和数据,还存储文件创建日期和时间、当前大小、上次修改日期等元信息。所有这些信息都称为文件系统的属性。常见的文件属性有
- 名称:它是以人类可理解的形式。
- 标识符:每个文件都由文件系统中的唯一标记号标识,称为标识符。
- 位置:设备上的文件位置。
- 类型:支持各种类型文件的系统需要此属性。
- 大小:当前文件大小的属性。
- 保护:分配和控制读、写和执行文件的访问权限。
- 时间、日期和安全:用于对文件的保护、安全,也用于监控
文件描述符
文件头 File Header;类似于Unix的 inode,在存储元数据中保存了每个文件的信息,保存文件的属性,跟踪哪一块存储块属于逻辑上文件结构的哪个偏移
文件描述符 (file-descriptor);是唯一标识操作系统中打开文件的数字(整形),用于用户和内核空间之间的接口,以识别 文件/Socket 资源。因此,当使用 open() 或 socket()(与内核接口的系统调用)时,会得到一个文件描述符,一个整数。因此,如果直接与内核交互,使用系统调用 read(), write() 等 close()。使用的是一个文件描述符句柄。
在 C 语言中 stdin,stdout、 和 stderr ,在 UNIX 中分别映射到文件描述符 0 1 2
f = open(name, flag);
...
... = read(f, ...);
...
close(f);
内核跟踪每个进程打开的文件:
- 操作系统为每个进程维护一个打开文件表
- 一个打开文件描述符是这个表中的索引
- 描述符由唯一的非负整数表示,例如 0、12 或 567。系统上每个打开的文件至少存在一个文件描述符
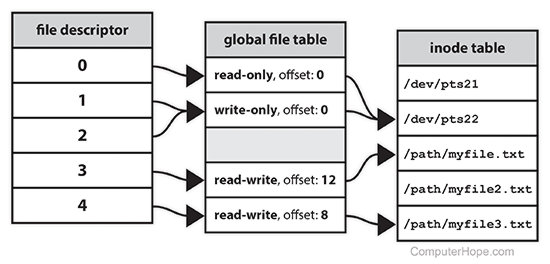
如果对文件需要更好的管理,就需要元数据来管理打开文件:
-
文件指针:指向最近的一次读写位置,每个打开了这个文件的进程都这个指针
-
文件打开计数:记录文件打开的次数; 当最后一个进程关闭了文件时,允许将其从打开文件表中移除
-
文件磁盘位置:缓存数据访问信息
-
访问权限:每个程序访问模式信息
从用户角度来看:文件是持久的数据结构
- 系统访问接口:
- 字节的集合(UNIX)
- 系统不会关心你想存储在磁盘上的任何的数据结构
- 操作系统内部视角:
- 块的集合(块是逻辑转换单元,而扇区是物理转换单元)
- 块大小<> 扇区大小:在UNIX中,块的大小是 4KB
空间管理
在系统层面上来看,存储设备在被划分为称为扇区的固定大小的块;扇区是存储设备上的最小存储单元 ,介于 512 bytes 和 4096bytes 之间;所有的操作都是操作磁盘块,读写1bytes也是对整个磁盘块的读写。
文件系统使用的是块,块是物理扇区的抽象
用户怎么访问文件:在系统层面需要知道用户的访问模式
- 顺序访问:按字节依次读取
- 几乎所有的访问都是这种方式
- 随机访问:从中间读写
- 不常用,但是仍然重要,如:虚拟内存支持文件,内存页存储在文件中;
- 更加快速,不希望获取文件中间的内容的时候也必须先获取块内所有字节
- 内容访问:通过特征(索引)
- 更多是数据库形式的存在;通过index,找到包含关系的文件
文件访问控制
多用户操作系统中的文件共享是很必要的,不是每个人都能够删除或修改他们没有权限的文件。
有关用户权限和文件所有权的数据在不同的操作系统上有不同的格式:
- 类 Unix被存储为访问控制列表 ;
Access-Control List(ACL) - Windows 上被存储为访问控制条目;
Access-Control Entries(ACE)
谁能够获得哪些文件的哪些访问权限
- 访问模式: 读,写,执行,删除,列举等
文件访问控制列表(ACL):
- <文件实体, 权限>
UNIX模式:
- <用户|组|物主,读|写|可执行>
- 用户ID识别用户;表明每个用户所允许的权限及保护模式
- 组ID允许用户组成组,并指定了组访问权限
多用户下,如何同时访问共享文件:
-
和进程同步算法相似
-
因磁盘IO和网络延迟而设计简单
-
文件共享的一致性语义
Consistency Semantics-
UNIX文件系统语义
Unix Semantics:-
对打开文件的写入内容立即对其他打开同一文件的其他用户可见
-
共享文件指针允许多用户同时读取和写入文件
-
-
会话语义
Session Semantics:- 用户对文件的写入对其他用户不可见。
- 文件关闭后,更改仅对新会话可见。
-
-
锁:
- 一些操作系统和文件系统提供该功能
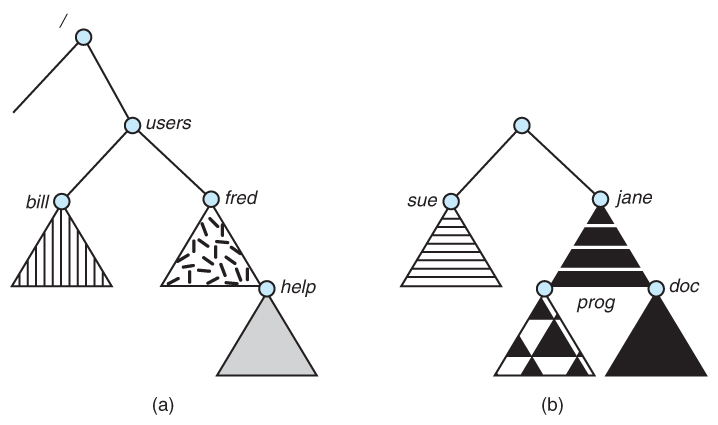
目录
目录是磁盘上的一个位置,是一种特殊的文件;用于对文件分层。文件夹和目录是可互换的术语。
目录的特点:
-
目录是一类特殊的文件:每个目录都包含了一张表
<name, pointer to file header> -
目录和文件的树形结构:早期的文件系统是扁平的(只有一层目录)
-
层次名称空间:

名字解析:逻辑名字转换成物理资源(如文件)的过程:
- 在文件系统中:到实际文件的文件名(路径)
- 遍历文件目录直到找到目标文件
- 举例:解析
/bin/ls- 读取root的文件头(在磁盘固定位置)
- 读取root的数据块: 搜索bin项
- 读取bin的文件头
- 读取bin的数据块: 搜索ls项
- 读取ls的文件头
当前工作目录:当前目录的内容存储在内存中可以快速的指向一个目录
- 每个进程都会指向一个文件目录用于解析文件名
- 允许用户指定相对路径来代替绝对路径
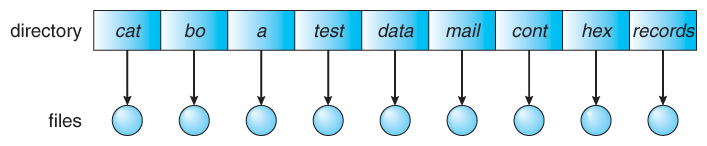
单级目录
单级目录 Single-Level Directory;单级目录理解起来比较简单,单级目录中所有文件都包含在同一目录中,必须具有唯一的名称
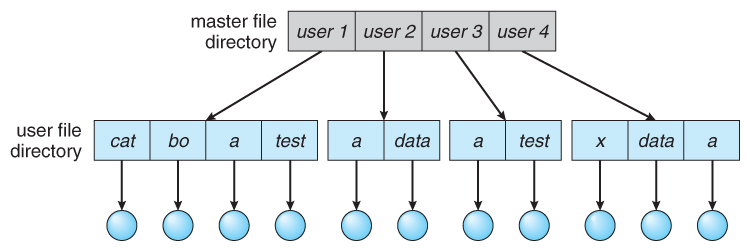
两级目录
两级目录 Two-Level Directory;两级目录通常为不同用户的自己的目录 User File Director UDF,文件名只需在指定目录下唯一即可。
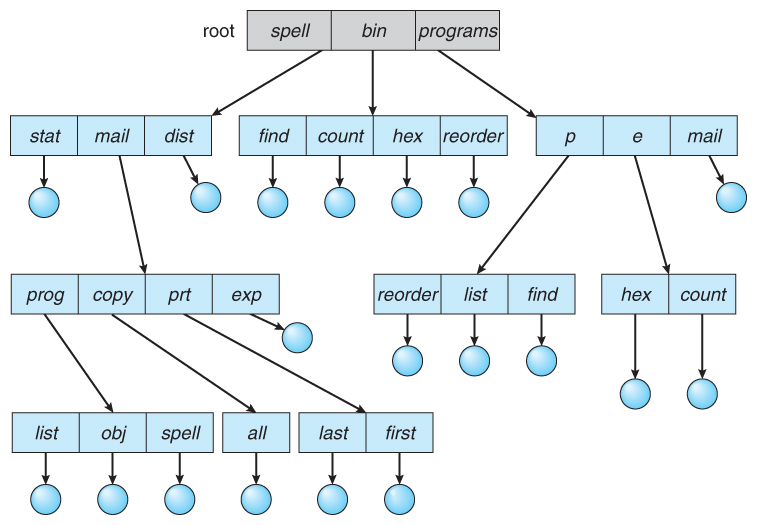
树形目录
树形目录 Tree-Structured Directories;通常是指深度大于2的目录,在此结构中,每个文件都有一个唯一的路径
文件别名
无环图目录
无环图目录 Acyclic-Graph Directories;也被称作为别名 Alias,是指在目录结构中一个文件有多个绝对位置(绝对路径)。UNIX中提供了两种类型的链接来实现该类型:
- 硬链接
hard link:硬链接会创建新的文件,指向同一个inode;在删除一个文件时,会删除一个指向底层 inode的链接。当所有指向该 inode 的链接都被删除,inode才会被删除(同一文件系统中的普通文件)- 每个文件都有引用计数器,以跟踪当前有多少文件引用该文件。每当删除其中一个引用(有别名的文件)时,计数器就会减少,当它达到零时,可以回收磁盘空间。
- 符号链接
symbolic link;也称软连接,是一个特殊文件,包含被链接文件的信息,可以是目录或文件。- 符号链接在删除或被移动时
- 找到所有链接并同时修改
- 符号链接悬空,
Dangling Pointer;不在有效
- 符号链接在删除或被移动时
Windows中仅支持符号链接,称为快捷方式
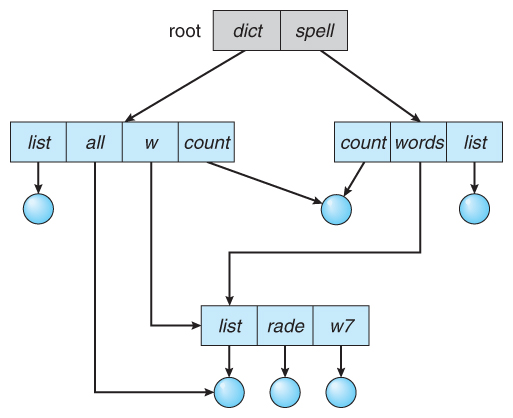
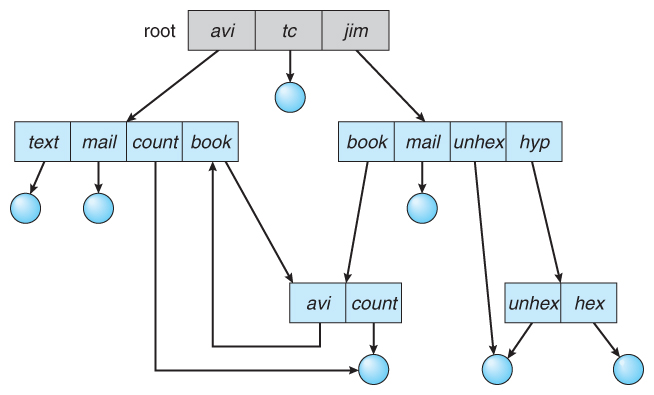
通用图目录
通用图目录 General Graph Directory ;是一种允许循环的目录;上述无环目录中是会进入无限循环
通用图目录比其他类型目录更佳灵活,最大问题是计算大小时的难度。通用图目录实现常见的是通过线性列表或哈希表:
- 线性列表:将所有文件保存在一个目录中,类似一个单链表。每个文件都包含一个数据块指向指针和目录中的下一个文件。
- 哈希表:目录中对于每个文件,都会生成一个键值对,将其存入哈希表中。借助文件名的哈希函数,我们可以确定存储在目录中的各个文件 key 和其指针
key points
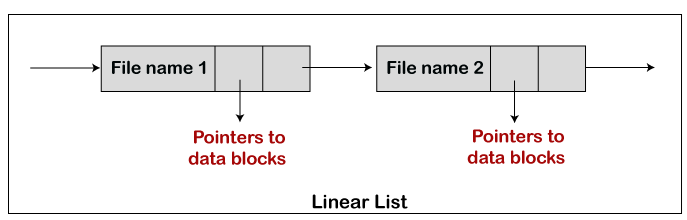
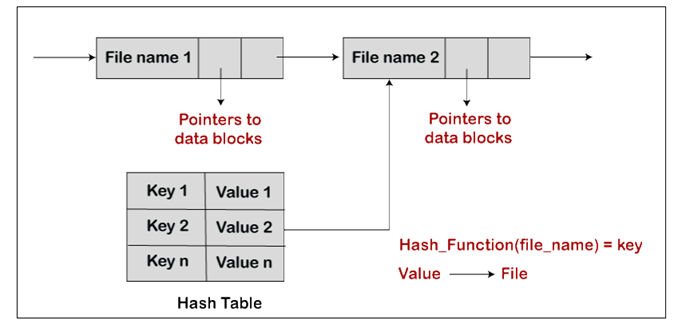
图:通用图目录结构
文件系统挂载
在类Unix系统中,VFS 会为每个分区或可移动存储设备分配一个设备 ID 如 dev/disk1s1;然后,创建一个虚拟目录树 ,并将每个设备的内容作为单独的目录放在该目录树下。
将目录分配给存储设备的行为称为挂载 mount,被分配的目录称为挂载点
- 一个文件系统需要先挂载才能被访问
- 一个未挂载的文件系统被挂载在挂载点上
文件系统种类
-
磁盘文件系统:文件存储在数据存储设备上,如磁盘; 例如: FAT,NTFS,ext2 3, ISO9660等
-
数据库文件系统:文件根据其特征是可被寻址的; 例如: WinFS
-
日志文件系统: 记录文件系统的修改,事件; 例如: journaling file system
-
网络,分布式文件系统:例如:NFS,SMB,AFS,GFS
-
虚拟文件系统
虚拟文件系统
虚拟文件系统 Virtual File Systems VFS;是对多种类型文件系统提供统一的通用API,使得在上层软件中,可以用单一的方式实现不同底层的文件系统。
虚拟文件系统的功能:
- 提供相同的文件和文件系统接口
- 管理所有文件和文件系统关联的数据结构
- 高效查询例程,遍历文件系统
- 与特定文件系统模块的交互
VFS除了统一的API外,还提供了唯一标识符 vnode;对于类UNIX操作系统中,inode是惟一的,并不会跨网络
Linux中虚拟文件系统的对象类型:
- inode:代表单个文件
- 存储文件的元信息(许可,拥有者,大小,数据库位置等)
- 一个文件对应一个inode,每个inode都由一个inode编号唯一标识
- 一个inode通常对应于存储在磁盘上的一个文件控制块
- file:代表一个打开的文件
- 存储进程和打开文件之间交互的信息。这个信息只存在于内核空间,不保存在磁盘上。
- superblock:卷控制块代表一个文件系统
- 每个文件系统一个
- 文件系统详细信息
- 块,块大小,空余块,计数,指针等
- dentry:代表目录项
dirctory entry- 用于将一个inode(文件)与一个目录关联
- 将目录项数据结构及树形布局编码成树形数据结构
- 指向文件控制块,父节点,项目列表等
数据块缓存
打开文件的数据结构
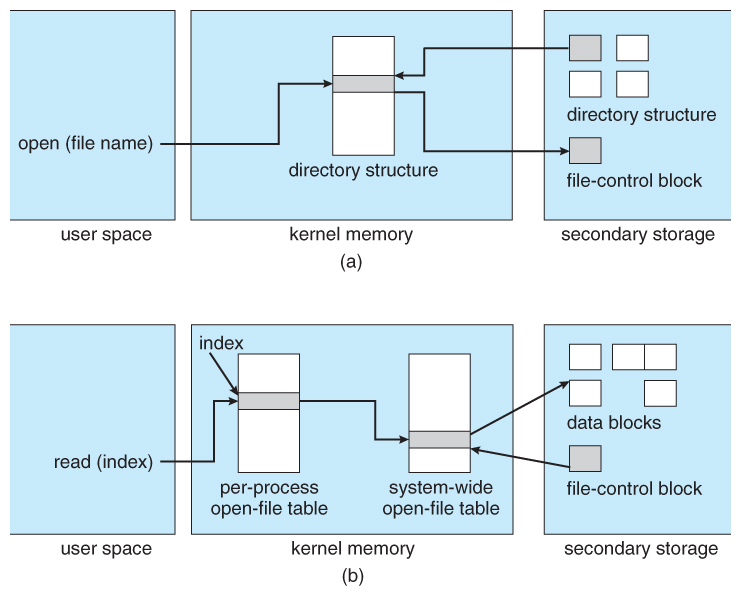
由图可知,当一个文件在程序中被访问时(创建、打开),open() 系统调用从磁盘读入FCB信息,并将其存储在系统打开文件表中。一个条目被添加到每个进程的打开文件表中,这个索引引用的是系统范围的打开文件表,并且进程表的索引由 open() 这个系统调用返回。这个索引称为文件描述符, Windows中为文件句柄。
如果有多个进程打开同一个文件,此时系统表中的计数器会递增。对应打开文件表条目会引用到系统表中
文件被关闭时,每个进程的打开文件表的条目被释放,系统表中的计数器递减。如果计数器到零,则系统表也被释放。
打开文件描述:
-
每个被打开的文件一个
-
文件状态信息
-
FCB:目录项,当前文件指针,文件操作设置等
打开文件表:
-
一个进程一个
-
一个系统级的
-
每个卷控制块也会保存一个列表
-
所以如果有文件被打开将不能被卸载
-
一些操作系统和文件系统提供该功能
调节对文件的访问
- 强制 - 根据锁保持情况和需求拒绝访问
- 劝告 - 进程可以查找锁的状态来决定怎么做
文件分配
在文件分配中,存在一些问题
大多数文件很小
- 需要对小文件支持
- 块的空间不能设置太小
一些文件却很大
- 必须支持大文件
- 大文件需要高效访问
磁盘的分配主要有三种方式:连续 contiguous、链式 linked 、索引 indexed ;分配指标必须遵循 高效的存储利用,与访问速度的表现
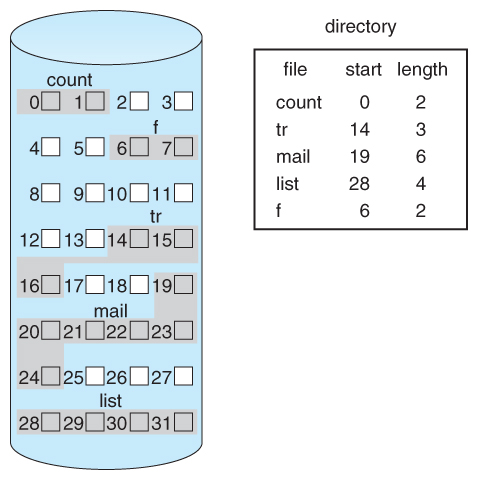
连续分配
连续分配 (Contiguous Allocation)是指文件的所有块连续地保存在一起
连续分配的特点:
-
只需要一个起始块,与长度
-
性能非常快,读取同一文件的连续块不需要移动磁头;或仅需要移动一小块到达相邻柱面
连续分配存在的问题:固定递归存储时不会出现问题,当文件增长或创建时文件的确切大小未知,会出现问题:
-
碎片:
-
过高估计文件最终的大小会增加外部碎片从而浪费浪费磁盘空间
-
文件增长超出其最初分配的空间,过低预估则可能需要移动文件位置或中止进程
-
-
文件增长问题:
- 如果一个文件初始分配大小很大,并长期没有写入,在文件填满时,很多空间将变得不可用
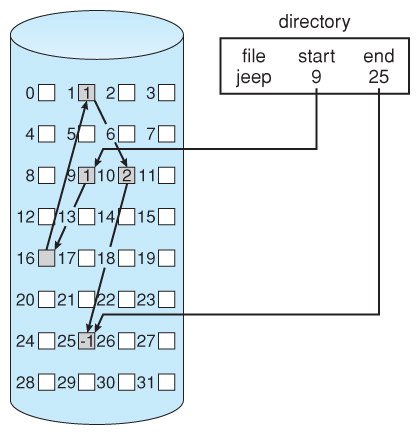
链式分配
链式分配( Linked Allocation )是指文件按照数据链表方式存储,并以每个链接消耗的存储空间为代价
链式分配的特点:
- 无外部碎片,无需预先知道文件大小,并支持文件的动态增长
链式分配的不足:
- 无法实现高效的随机访问;链式访问仅可以串行访问文件,必须从每个位置的列表头开始
- 可靠性:指针丢失或损坏
索引分配
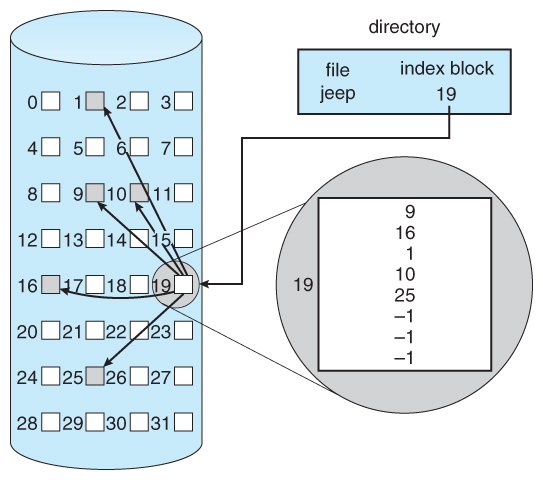
索引分配(Indexed Allocation)是指将每个文件的索引组合在一个公共块上,每个索引项指向了一个数据块
索引分配的特点:基本包含链式分配和连续分配的所有优点
索引分配的不足:会浪费一部分磁盘空间
- 无论文件大小,存储索引都有一定开销(文件大小<索引大小)
- 单个索引块不能保存大文件的所有指针
对于单个索引块不能保存大文件的所有指针这个问题,一般情况下有下述解决方案
- 链式索引块模式
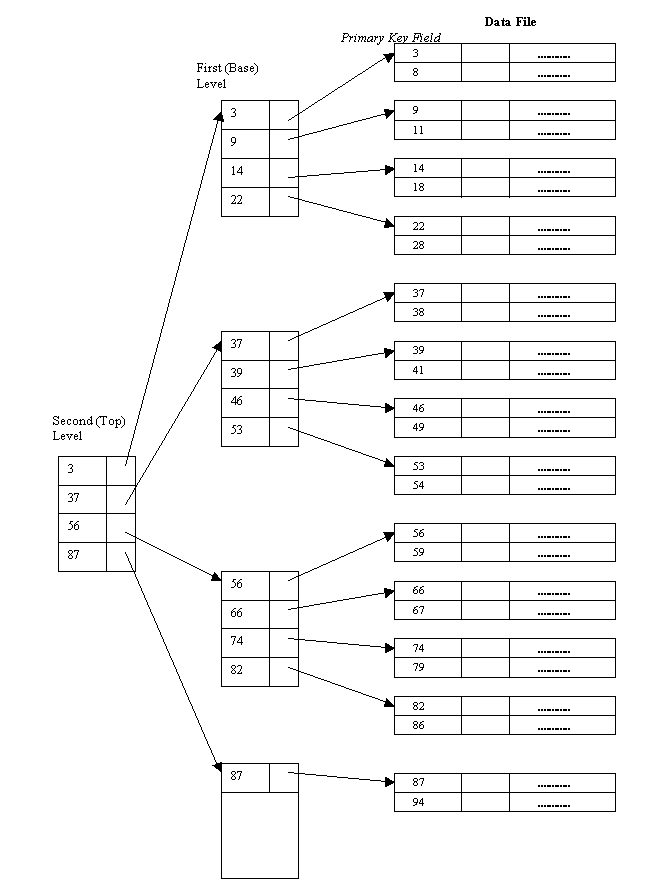
Linked Scheme:索引块为一个磁盘块,第一个索引块包含一些头信息、前 N 个块地址;还包含指向其他链接索引块的指针 - 多级索引
Multi-Level Index:类似于多级页表,第一个索引块包含一组指向二级索引块的指针,而二级索引块又包含指向实际数据块的指针 - 联合模式
Combined Scheme:
Reference
空闲空间管理
空闲空间管理只是磁盘管理中,需要追踪和分配对空闲空间部分的管理,对于空闲空间的管理的表现是位图 bitmap;即通过位向量来标记数据块的使用情况
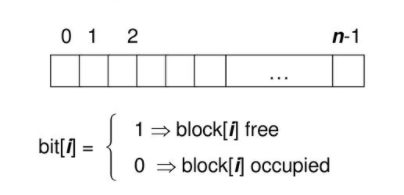
其他管理空闲空间的方式:
- 链表:链表也可以作为管理空闲块的一种方式
- 分组:将空闲块存储在第一个空闲块中,前
n-1个空闲块是空闲的,最后一个包含下一个分组 - 计数:存储一个磁盘块的地址和之后n个空闲块的数量
Reference
多磁盘管理 RAID
冗余磁盘阵列 **RAID **(redundant array of independent disks);是一种小磁盘分区组成大分区的一种解决方案,一种磁盘管理技术
RAID的工作原理
RAID 的工作原理是将数据分别放置在多个磁盘上,并允许I/O操作以平衡的方式,从而提高磁盘性能
RAID Controller
RAID 控制器是用于管理存储阵列中的硬盘驱动器的设备,是操作系统和物理磁盘中间的一个抽象层,将磁盘表示为逻辑单元。
RAID控制器分为软RAID和硬RAID
- 硬RAID
Hardware RAID:物理控制器管理整个磁盘阵列;如主板或RAID卡 - 软RAID
Software RAID:使用硬件资源来管理磁盘阵列;如CPU、内存;软RAID可能无法实现性能提升,反而影响性能
RAID级别
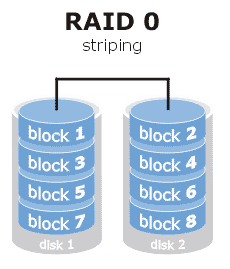
RAID0
RAID0(无容错的条带化磁盘阵列),是将数据体划分为块并将数据块分布在独立磁盘冗余阵列中的多个存储设备中,但不提供容错。
RAID1
RAID1又称为磁盘镜像 mirroring,将数据复制到两个或更多磁盘,由至少两个数据存储驱动器组成,读性能提升,写性能与单磁盘相同。RAID1提供了全面的数据保护
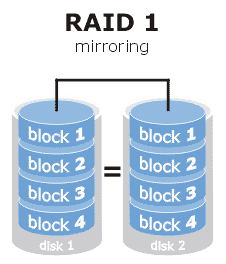
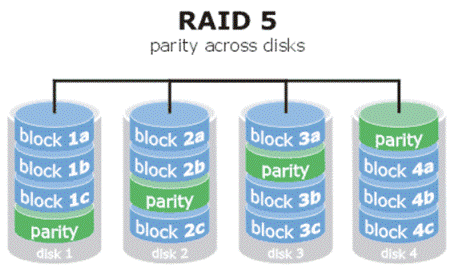
RAID5
RAID0(基于奇偶校验块的条带化磁盘阵列);它使用类似于 RAID0 的分布式数据存储,但通过包含写入不同阵列磁盘的冗余信息(奇偶校验码)来提高数据存储的可靠性。RAID 5 至少需要三个磁盘,但出于性能原因,通常建议使用至少五个磁盘。
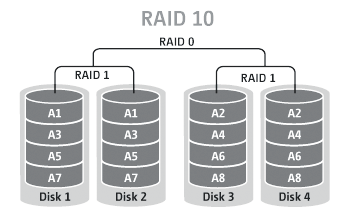
RAID 10
RAID 0+1是结合 RAID 1 和 RAID 0的一种模式,通常称为 RAID 10;RAID10需要至少四个磁盘;通过跨镜像的条带化保存数据,只要每个镜像对中的一个磁盘正常,那么数据就正常
磁盘调度
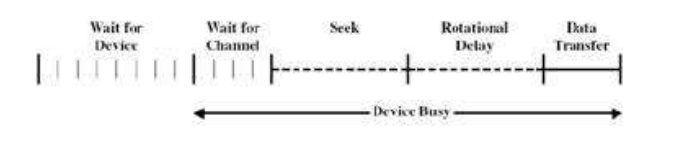
磁盘调度是指在操作系统层面重新组织IO请求的顺序,来有效的减少磁盘访问开销。
在传统磁盘中由多个盘面组成,每个盘面被臂组件上的磁盘头来通过旋转读取,通过所希望的扇区开始
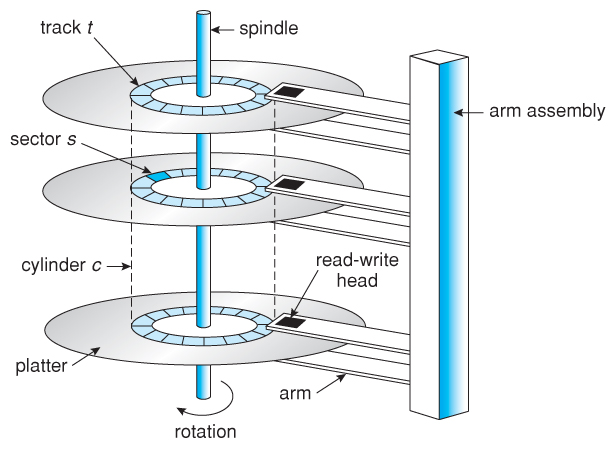
在操作中,磁盘会告诉旋转例如 7200RPM(revolutions per minute)(实际读写速度120 MB/s )。数据从磁盘传输到计算机的速率由几个步骤组成:
- 寻道时间
seek time:是将磁头从一个柱面移动到另一个柱面所需的时间,以及磁头在移动后稳定下来所需的时间。是过程中最慢的步骤,也是整体传输速率的主要瓶颈。 - 旋转延迟
rotational latency:扇区从开始处到目的处所需时间 - 传输速率
transfer rate:数据从磁盘移动到计算机所需的时间
$access\ time=SK+RL+TR$
- $T_a$ access time 访问时间
- $T_s$ seek time 寻址时间
- $T_r$ rotational latency 旋转延迟
- $T$ transfer time 传输速率
- $b$ transfer b bytes 传输位
- $N $ bytes per track 每轨存多少字节
- $r$ Rotational speed
- $\frac{1}{r}$ 旋转一周的时间
- $\frac{1}{2r}$ 平均旋转延迟,旋转一周时间再取一半
- $\frac{b}{rN}$ 数据访问时间
那么 传输速率 $T = \frac{b}{rN}$
平均访问时间为 $T_a = T_s + \frac{1}{2r} + \frac{b}{rN}$
如:$T_s = 2ms$,$r=10000rpm$,512B扇区大小,每轨320个扇区, 1.3 MB的文件大小
-
转一圈的时间:RPM=10000时,每6毫秒转一圈:$\frac{1}{r} = \frac{60}{10000}=0.006s = 6ms$
-
一个文件有多少扇区:$\frac{1.3MB}{512} = \frac{1300000}{512}=2540$
-
一共多少轨道:$2540\div320=8$
通过磁道 tracks 访问需要耗时多少?
-
一个磁道要传输的数据大小:$b=512\times320$
-
每轨有多少字节:$N=512\times320$
-
$\frac{1}{r}=6$,$\frac{1}{2r} = 3$
-
$\frac{b}{rN}=6$ ;因$b=N$ 故$\frac{b}{rN}=6$
-
因 $T_s=2$,$Average T_r=3$,$\frac{b}{rN}=6$ ;那么 $T_a = T_s + \frac{1}{2r} + \frac{b}{rN}=2+3+6=11$
-
那么按轨寻址访问的总时间为:$8*11=88ms$
通过扇区 sectors 访问需要耗时多少?
- 每轨多少字节 $N=512\times320$
- 因磁轨转一圈多少时间 $\frac{1}{r} = 6$,$\frac{1}{2r} = 3$;每磁道耗时 $\frac{1}{r} = \frac{6}{320} = 0.01875ms$
- 因 $\frac{1}{r} = \frac{6}{320}$ ;$b=512$;$N=512\times320$;那么 $\frac{b}{rN}=0.01875$
- 那么一个扇区的时间为:
- 因 $T_s=2$,$Average T_r=3$,$\frac{b}{rN}=0.01875$
- b=512,N=512,$\frac{1}{r} = 0.01875$,那么,$\frac{b}{rN}=0.01875$
- 那么 $T_a = T_s + aT_r + \frac{n}{rN} = 2+3+0.01875 = 5.01875$
- 那么总共时间为 $2540*5.01875=12748ms$
- 因 $T_s=2$,$Average T_r=3$,$\frac{b}{rN}=0.01875$
那么就可以得出结论:
- 寻道方式是性能上区别的原因
- 如果来回寻道,会导致性能急剧下降
- 对单个磁盘,会有一个IO请求数目
- 如果请求是随机的,那么会表现很差
磁盘调度算法
-
磁盘传输速度主要受寻道时间和旋转延迟的限制。当要处理多个请求时,在等待其他请求被处理时也会有一些固有的延迟。
-
带宽是通过传输的数据量除以从发出第一个请求到完成最后一次传输的总时间量来衡量的
-
通过以良好的顺序处理请求,可以提高带宽和访问时间。
-
磁盘请求包括磁盘地址、内存地址、要传输的扇区数以及请求是读还是写。
FCFS
先来先服务 First-Come First-Serve:
- 按顺序处理请求
- 公平对待所有进程
- 在有很多进程的情况下,接近随机调度的性能
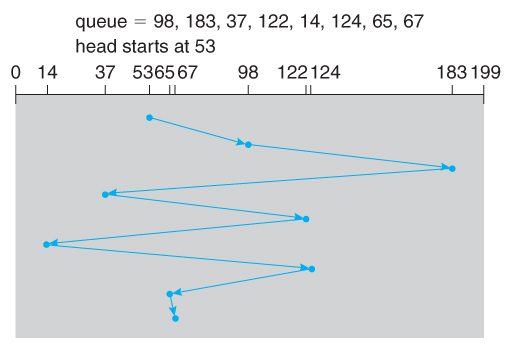
可以看到柱面 cylinder从122 到 14 在回到124摆动很巨大:
SSTF
最短寻道优先 Shortest Seek Time First
- 选择从磁臂当前位置需要移动最少的IO请求
- 总是选择最短寻道时间
- 可能会导致饥饿
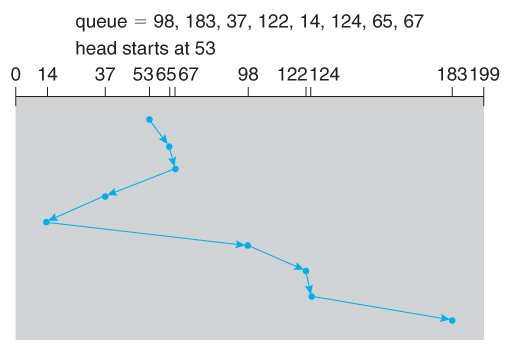
由图可以看出相同的情况下SSTF将柱面移动数减少到 236 个柱面,低于**FCFS **所需的 640 个柱面。
SCAN
SCAN算法,又称电梯算法,磁臂在一个方向上移动,满足所有为完成的请求,直到磁臂到达该方向上最后的磁道,类似于在高层建筑中处理请求的电梯。
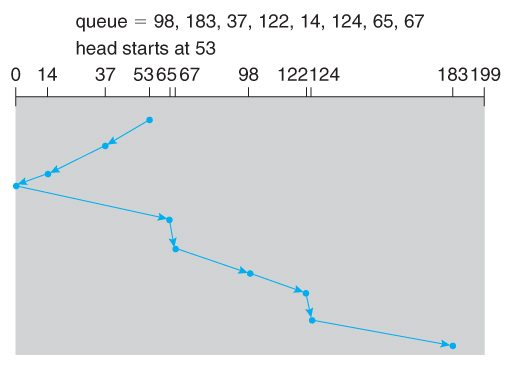
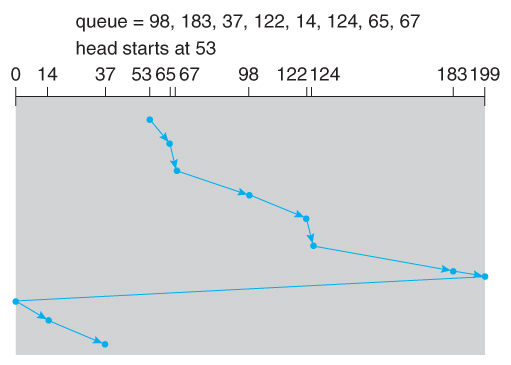
C-SCAN
Circular-SCAN,通过循环队列方式来改进 SCAN :一旦磁臂到达磁盘的末端,它会返回到另一端而不处理任何请求,然后从磁盘的开头重新开始:
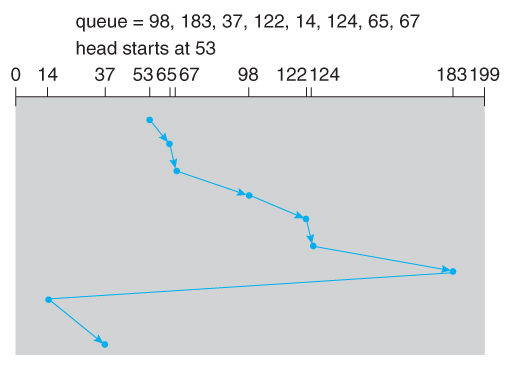
LOOK
LOOK是通过待处理请求的队列来改进SCAN,而不是磁盘序列,并且不会将磁头移向磁盘末端的距离超过必要的位置。
N-Step LOOK or N-Step-SCAN
N-Step-SCAN是将请求队列分为成长度为N的子队列,使用SCAN算法进行处理;当在一个队列的处理过程中,如果有一些新的请求到达,那么它们必须被放置在另一个队列中。
设有从 0 到 199 编号为 200 磁道;请求顺序为, 122、90、160、24、102、89、143、18、67;$N=2$
子队列有:
-
1 = {122, 90}
-
2 = {160, 24}
-
3 = {102, 89}
-
4 = {143, 18}
-
5 = {67}
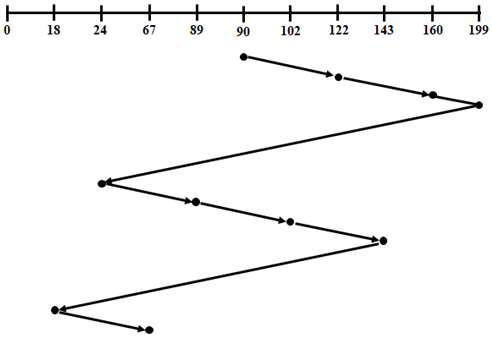
N-step-SCAN 磁盘调度算法的吞吐量高,平均响应时间低。
Reference
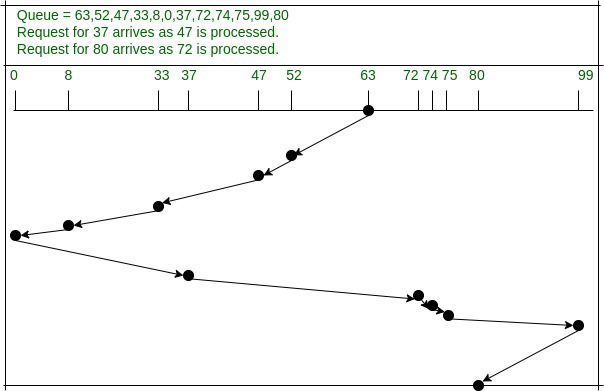
FSCAN
FSCAN Fixed period SCAN,是 N-step-SCAN 的简化版本,FSCAN将磁盘请求队列分成两个子队列,一个是由当前所有请求磁盘I/O的进程所形成的队列,由磁盘调度按SCAN算法进行处理,在扫描期间,将新出现的请求磁盘I/O的进程放入另一个等待处理的请求队列。这样,所有的新请求都被推迟到下一次扫描时处理。
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2022/05/ch13-file-system/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。