本文发布于Cylon的收藏册,转载请著名原文链接~
Overview
本文将引入一个思路:“在Kubernetes集群发生网络异常时如何排查”。文章将引入Kubernetes 集群中网络排查的思路,包含网络异常模型,常用工具,并且提出一些案例以供学习。
- Pod常见网络异常分类
- 网络排查工具
- Pod网络异常排查思路及流程模型
- CNI网络异常排查步骤
- 案例学习
Pod网络异常
网络异常大概分为如下几类:
-
网络不可达,主要现象为ping不通,其可能原因为:
- 源端和目的端防火墙(
iptables,selinux)限制 - 网络路由配置不正确
- 源端和目的端的系统负载过高,网络连接数满,网卡队列满
- 网络链路故障
- 源端和目的端防火墙(
-
端口不可达:主要现象为可以ping通,但telnet端口不通,其可能原因为:
- 源端和目的端防火墙限制
- 源端和目的端的系统负载过高,网络连接数满,网卡队列满,端口耗尽
- 目的端应用未正常监听导致(应用未启动,或监听为127.0.0.1等)
-
DNS解析异常:主要现象为基础网络可以连通,访问域名报错无法解析,访问IP可以正常连通。其可能原因为
- Pod的DNS配置不正确
- DNS服务异常
- pod与DNS服务通讯异常
-
大数据包丢包:主要现象为基础网络和端口均可以连通,小数据包收发无异常,大数据包丢包。可能原因为:
- 数据包的大小超过了 dockero,CNI 插件,或者宿主机网卡的 MTU 值。
- 可使用
ping -s指定数据包大小进行测试
- 可使用
- 数据包的大小超过了 dockero,CNI 插件,或者宿主机网卡的 MTU 值。
-
CNI异常:主要现象为Node可以通,但Pod无法访问集群地址,可能原因有:
- kube-proxy 服务异常,没有生成 iptables 策略或者 ipvs 规则导致无法访问
- CIDR耗尽,无法为Node注入
PodCIDR导致 CNI 插件异常 - 其他 CNI 插件问题
那么整个Pod网络异常分类可以如下图所示:
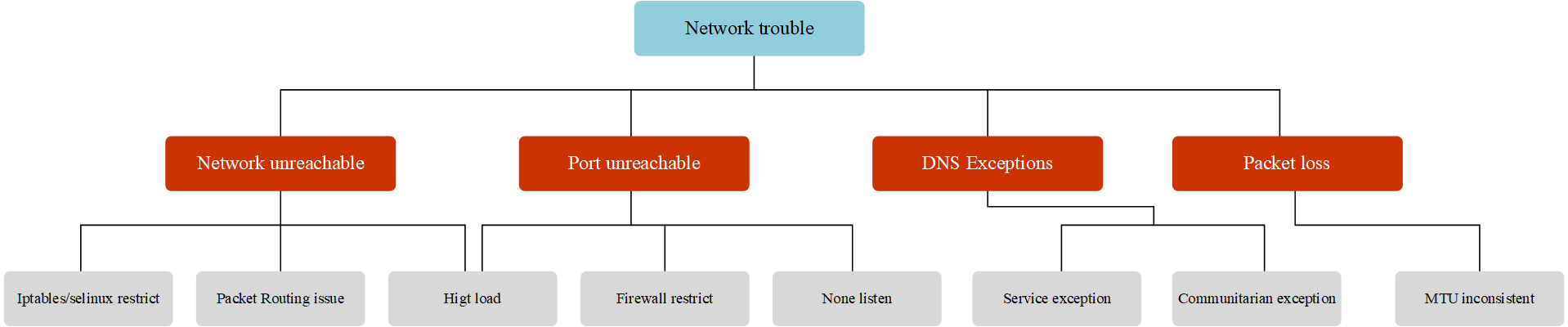
总结一下,Pod最常见的网络故障有,网络不可达(ping不通);端口不可达(telnet不通);DNS解析异常(域名不通)与大数据包丢失(大包不通)。
常用网络排查工具
在了解到常见的网络异常后,在排查时就需要使用到一些网络工具才可以很有效的定位到网络故障原因,下面会介绍一些网络排查工具。
tcpdump [1]
tcpdump网络嗅探器,将强大和简单结合到一个单一的命令行界面中,能够将网络中的报文抓取,输出到屏幕或者记录到文件中。
各系统下的安装
- Ubuntu/Debian:
tcpdump;apt-get install -y tcpdump- Centos/Fedora:
tcpdump;yum install -y tcpdump- Apline:
tcpdump;apk add tcpdump --no-cache
查看指定接口上的所有通讯
语法
| 参数 | 说明 |
|---|---|
| -i [interface] | |
| -w [flle] | 第一个n表示将地址解析为数字格式而不是主机名,第二个N表示将端口解析为数字格式而不是服务名 |
| -n | 不显示IP地址 |
| -X | hex and ASCII |
| -A | ASCII(实际上是以人类可读懂的包进行显示) |
| -XX | |
| -v | 详细信息 |
| -r | 读取文件而不是实时抓包 |
| 关键字 | |
| type | host(主机名,域名,IP地址), net, port, portrange |
| direction | src, dst, src or dst , src and ds |
| protocol | ether, ip,arp, tcp, udp, wlan |
捕获所有网络接口
tcpdump -D
####按IP查找流量
最常见的查询之一 host,可以看到来往于 1.1.1.1 的流量。
tcpdump host 1.1.1.1
####按源/目的 地址过滤
如果只想查看来自/向某方向流量,可以使用 src 和 dst。
tcpdump src|dst 1.1.1.1
通过网络查找数据包
使用 net 选项,来要查找出/入某个网络或子网的数据包。
tcpdump net 1.2.3.0/24
使用十六进制输出数据包内容
hex 可以以16进制输出包的内容
tcpdump -c 1 -X icmp
查看特定端口的流量
使用 port 选项来查找特定的端口流量。
tcpdump port 3389
tcpdump src port 1025
查找端口范围的流量
tcpdump portrange 21-23
过滤包的大小
如果需要查找特定大小的数据包,可以使用以下选项。你可以使用 less,greater。
tcpdump less 32
tcpdump greater 64
tcpdump <= 128
捕获流量输出为文件
-w 可以将数据包捕获保存到一个文件中以便将来进行分析。这些文件称为PCAP(PEE-cap)文件,它们可以由不同的工具处理,包括 Wireshark 。
tcpdump port 80 -w capture_file
组合条件
tcpdump也可以结合逻辑运算符进行组合条件查询
-
AND
andor&& -
OR
oror|| -
EXCEPT
notor!
tcpdump -i eth0 -nn host 220.181.57.216 and 10.0.0.1 # 主机之间的通讯
tcpdump -i eth0 -nn host 220.181.57.216 or 10.0.0.1
# 获取10.0.0.1与 10.0.0.9或 10.0.0.1 与10.0.0.3之间的通讯
tcpdump -i eth0 -nn host 10.0.0.1 and \(10.0.0.9 or 10.0.0.3\)
原始输出
并显示人类可读的内容进行输出包(不包含内容)。
tcpdump -ttnnvvS -i eth0
tcpdump -ttnnvvS -i eth0
IP到端口
让我们查找从某个IP到端口任何主机的某个端口所有流量。
tcpdump -nnvvS src 10.5.2.3 and dst port 3389
去除特定流量
可以将指定的流量排除,如这显示所有到192.168.0.2的 非ICMP的流量。
tcpdump dst 192.168.0.2 and src net and not icmp
来自非指定端口的流量,如,显示来自不是SSH流量的主机的所有流量。
tcpdump -vv src mars and not dst port 22
选项分组
在构建复杂查询时,必须使用单引号 '。单引号用于忽略特殊符号 () ,以便于使用其他表达式(如host, port, net等)进行分组。
tcpdump 'src 10.0.2.4 and (dst port 3389 or 22)'
过滤TCP标记位
TCP RST
The filters below find these various packets because tcp[13] looks at offset 13 in the TCP header, the number represents the location within the byte, and the !=0 means that the flag in question is set to 1, i.e. it’s on.
tcpdump 'tcp[13] & 4!=0'
tcpdump 'tcp[tcpflags] == tcp-rst'
TCP SYN
tcpdump 'tcp[13] & 2!=0'
tcpdump 'tcp[tcpflags] == tcp-syn'
同时忽略SYN和ACK标志的数据包
tcpdump 'tcp[13]=18'
TCP URG
tcpdump 'tcp[13] & 32!=0'
tcpdump 'tcp[tcpflags] == tcp-urg'
TCP ACK
tcpdump 'tcp[13] & 16!=0'
tcpdump 'tcp[tcpflags] == tcp-ack'
TCP PSH
tcpdump 'tcp[13] & 8!=0'
tcpdump 'tcp[tcpflags] == tcp-push'
TCP FIN
tcpdump 'tcp[13] & 1!=0'
tcpdump 'tcp[tcpflags] == tcp-fin'
查找http包
查找 user-agent 信息
tcpdump -vvAls0 | grep 'User-Agent:'
查找只是 GET 请求的流量
tcpdump -vvAls0 | grep 'GET'
查找http客户端IP
tcpdump -vvAls0 | grep 'Host:'
查询客户端cookie
tcpdump -vvAls0 | grep 'Set-Cookie|Host:|Cookie:'
查找DNS流量
tcpdump -vvAs0 port 53
查找对应流量的明文密码
tcpdump port http or port ftp or port smtp or port imap or port pop3 or port telnet -lA | egrep -i -B5 'pass=|pwd=|log=|login=|user=|username=|pw=|passw=|passwd= |password=|pass:|user:|username:|password:|login:|pass |user '
wireshark追踪流
wireshare追踪流可以很好的了解出在一次交互过程中都发生了那些问题。
wireshare选中包,右键选择 “追踪流“ 如果该包是允许的协议是可以打开该选项的
关于抓包节点和抓包设备
如何抓取有用的包,以及如何找到对应的接口,有以下建议
抓包节点:
通常情况下会在==源端==和==目的端==两端同时抓包,观察数据包是否从源端正常发出,目的端是否接收到数据包并给源端回包,以及源端是否正常接收到回包。如果有丢包现象,则沿网络链路上各节点抓包排查。例如,A节点经过c节点到B节点,先在AB两端同时抓包,如果B节点未收到A节点的包,则在c节点同时抓包。
抓包设备:
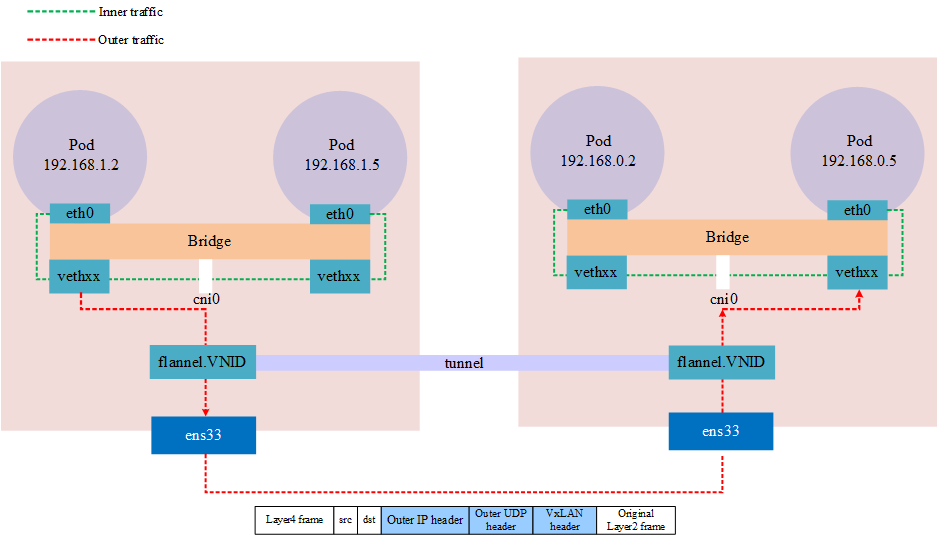
对于 Kubernetes 集群中的Pod,由于容器内不便于抓包,通常视情况在Pod数据包经过的veth设备,docker0 网桥,CNI 插件设备(如cni0,flannel.1 etc..)及Pod所在节点的网卡设备上指定Pod IP进行抓包。选取的设备根据怀疑导致网络问题的原因而定,比如范围由大缩小,从源端逐渐靠近目的端,比如怀疑是 CNI 插件导致,则在 CNI 插件设备上抓包。从pod发出的包逐一经过veth设备,cni0 设备,flannel0,宿主机网卡,到达对端,抓包时可按顺序逐一抓包,定位问题节点。
需要注意在不同设备上抓包时指定的源目IP地址需要转换,如抓取某Pod时,ping {host} 的包,在 veth 和 cni0 上可以指定 Pod IP抓包,而在宿主机网卡上如果仍然指定Pod IP会发现抓不到包,因为此时Pod IP已被转换为宿主机网卡IP。
下图是一个使用 VxLAN 模式的 flannel 的跨界点通讯的网络模型,在抓包时需要注意对应的网络接口
nsenter
nsenter是一款可以进入进程的名称空间中。例如,如果一个容器以非 root 用户身份运行,而使用 docker exec 进入其中后,但该容器没有安装 sudo 或未 netstat ,并且您想查看其当前的网络属性,如开放端口,这种场景下将如何做到这一点?nsenter 就是用来解决这个问题的。
nsenter (namespace enter) 可以在容器的宿主机上使用 nsenter 命令进入容器的命名空间,以容器视角使用宿主机上的相应网络命令进行操作。==当然需要拥有 root 权限==
各系统下的安装 [2]
- Ubuntu/Debian:
util-linux;apt-get install -y util-linux- Centos/Fedora:
util-linux;yum install -y util-linux- Apline:
util-linux;apk add util-linux --no-cache
nsenter 的使用语法为,nsenter -t pid -n <commond>,-t 接 进程ID号,-n 表示进入名称空间内,<commond> 为执行的命令。更多的内容可以参考 [3]
实例:如我们有一个Pod进程ID为30858,进入该Pod名称空间内执行 ifconfig ,如下列所示
$ ps -ef|grep tail
root 17636 62887 0 20:19 pts/2 00:00:00 grep --color=auto tail
root 30858 30838 0 15:55 ? 00:00:01 tail -f
$ nsenter -t 30858 -n ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1480
inet 192.168.1.213 netmask 255.255.255.0 broadcast 192.168.1.255
ether 5e:d5:98:af:dc:6b txqueuelen 0 (Ethernet)
RX packets 92 bytes 9100 (8.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92 bytes 8422 (8.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 5 bytes 448 (448.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5 bytes 448 (448.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
net1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.1.0.201 netmask 255.255.255.0 broadcast 10.1.0.255
ether b2:79:f9:dd:2a:10 txqueuelen 0 (Ethernet)
RX packets 228 bytes 21272 (20.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 216 bytes 20272 (19.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
如何定位Pod名称空间
首先需要确定Pod所在的节点名称
$ kubectl get pods -owide |awk '{print $1,$7}'
NAME NODE
netbox-85865d5556-hfg6v master-machine
netbox-85865d5556-vlgr4 node01
如果Pod不在当前节点还需要用IP登录则还需要查看IP(可选)
$ kubectl get pods -owide |awk '{print $1,$6,$7}'
NAME IP NODE
netbox-85865d5556-hfg6v 192.168.1.213 master-machine
netbox-85865d5556-vlgr4 192.168.0.4 node01
接下来,登录节点,获取容器lD,如下列所示,每个pod默认有一个 pause 容器,其他为用户yaml文件中定义的容器,理论上所有容器共享相同的网络命名空间,排查时可任选一个容器。
$ docker ps |grep netbox-85865d5556-hfg6v
6f8c58377aae f78dd05f11ff "tail -f" 45 hours ago Up 45 hours k8s_netbox_netbox-85865d5556-hfg6v_default_4a8e2da8-05d1-4c81-97a7-3d76343a323a_0
b9c732ee457e registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 "/pause" 45 hours ago Up 45 hours k8s_POD_netbox-85865d5556-hfg6v_default_4a8e2da8-05d1-4c81-97a7-3d76343a323a_0
接下来获得获取容器在节点系统中对应的进程号,如下所示
$ docker inspect --format "{{ .State.Pid }}" 6f8c58377aae
30858
最后就可以通过 nsenter 进入容器网络空间执行命令了
paping
paping 命令可对目标地址指定端口以TCP协议进行连续ping,通过这种特性可以弥补 ping ICMP协议,以及 nmap , telnet 只能进行一次操作的的不足;通常情况下会用于测试端口连通性和丢包率
paping download:paping
paping 还需要安装以下依赖,这取决于你安装的 paping 版本
- RedHat/CentOS:
yum install -y libstdc++.i686 glibc.i686 - Ubuntu/Debian:最小化安装无需依赖
$ paping -h
paping v1.5.5 - Copyright (c) 2011 Mike Lovell
Syntax: paping [options] destination
Options:
-?, --help display usage
-p, --port N set TCP port N (required)
--nocolor Disable color output
-t, --timeout timeout in milliseconds (default 1000)
-c, --count N set number of checks to N
mtr
mtr 是一个跨平台的网络诊断工具,将 traceroute 和 ping 的功能结合到一个工具。与 traceroute 不同的是 mtr 显示的信息比起 traceroute 更加丰富:通过 mtr 可以确定网络的条数,并且可以同时打印响应百分比以及网络中各跳跃点的响应时间。
各系统下的安装 [2]
- Ubuntu/Debian:
mtr;apt-get install -y mtr- Centos/Fedora:
mtr;yum install -y mtr- Apline:
mtr;apk add mtr --no-cache
简单的使用示例
最简单的示例,就是后接域名或IP,这将跟踪整个路由
$ mtr google.com
Start: Thu Jun 28 12:10:13 2018
HOST: TecMint Loss% Snt Last Avg Best Wrst StDev
1.|-- 192.168.0.1 0.0% 5 0.3 0.3 0.3 0.4 0.0
2.|-- 5.5.5.211 0.0% 5 0.7 0.9 0.7 1.3 0.0
3.|-- 209.snat-111-91-120.hns.n 80.0% 5 7.1 7.1 7.1 7.1 0.0
4.|-- 72.14.194.226 0.0% 5 1.9 2.9 1.9 4.4 1.1
5.|-- 108.170.248.161 0.0% 5 2.9 3.5 2.0 4.3 0.7
6.|-- 216.239.62.237 0.0% 5 3.0 6.2 2.9 18.3 6.7
7.|-- bom05s12-in-f14.1e100.net 0.0% 5 2.1 2.4 2.0 3.8 0.5
-n 强制 mtr 打印 IP地址而不是主机名
$ mtr -n google.com
Start: Thu Jun 28 12:12:58 2018
HOST: TecMint Loss% Snt Last Avg Best Wrst StDev
1.|-- 192.168.0.1 0.0% 5 0.3 0.3 0.3 0.4 0.0
2.|-- 5.5.5.211 0.0% 5 0.9 0.9 0.8 1.1 0.0
3.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
4.|-- 72.14.194.226 0.0% 5 2.0 2.0 1.9 2.0 0.0
5.|-- 108.170.248.161 0.0% 5 2.3 2.3 2.2 2.4 0.0
6.|-- 216.239.62.237 0.0% 5 3.0 3.2 3.0 3.3 0.0
7.|-- 172.217.160.174 0.0% 5 3.7 3.6 2.0 5.3 1.4
-b 同时显示IP地址与主机名
$ mtr -b google.com
Start: Thu Jun 28 12:14:36 2018
HOST: TecMint Loss% Snt Last Avg Best Wrst StDev
1.|-- 192.168.0.1 0.0% 5 0.3 0.3 0.3 0.4 0.0
2.|-- 5.5.5.211 0.0% 5 0.7 0.8 0.6 1.0 0.0
3.|-- 209.snat-111-91-120.hns.n 0.0% 5 1.4 1.6 1.3 2.1 0.0
4.|-- 72.14.194.226 0.0% 5 1.8 2.1 1.8 2.6 0.0
5.|-- 108.170.248.209 0.0% 5 2.0 1.9 1.8 2.0 0.0
6.|-- 216.239.56.115 0.0% 5 2.4 2.7 2.4 2.9 0.0
7.|-- bom07s15-in-f14.1e100.net 0.0% 5 3.7 2.2 1.7 3.7 0.9
-c 跟一个具体的值,这将限制 mtr ping的次数,到达次数后会退出
$ mtr -c5 google.com
如果需要指定次数,并且在退出后保存这些数据,使用 -r flag
$ mtr -r -c 5 google.com > 1
$ cat 1
Start: Sun Aug 21 22:06:49 2022
HOST: xxxxx.xxxxx.xxxx.xxxx Loss% Snt Last Avg Best Wrst StDev
1.|-- gateway 0.0% 5 0.6 146.8 0.6 420.2 191.4
2.|-- 212.xx.21.241 0.0% 5 0.4 1.0 0.4 2.3 0.5
3.|-- 188.xxx.106.124 0.0% 5 0.7 1.1 0.7 2.1 0.5
4.|-- ??? 100.0 5 0.0 0.0 0.0 0.0 0.0
5.|-- 72.14.209.89 0.0% 5 43.2 43.3 43.1 43.3 0.0
6.|-- 108.xxx.250.33 0.0% 5 43.2 43.1 43.1 43.2 0.0
7.|-- 108.xxx.250.34 0.0% 5 43.7 43.6 43.5 43.7 0.0
8.|-- 142.xxx.238.82 0.0% 5 60.6 60.9 60.6 61.2 0.0
9.|-- 142.xxx.238.64 0.0% 5 59.7 67.5 59.3 89.8 13.2
10.|-- 142.xxx.37.81 0.0% 5 62.7 62.9 62.6 63.5 0.0
11.|-- 142.xxx.229.85 0.0% 5 61.0 60.9 60.7 61.3 0.0
12.|-- xx-in-f14.1e100.net 0.0% 5 59.0 58.9 58.9 59.0 0.0
默认使用的是 ICMP 协议 -i ,可以指定 -u, -t 使用其他协议
mtr --tcp google.com
-m 指定最大的跳数
mtr -m 35 216.58.223.78
-s 指定包的大小
mtr输出的数据
| colum | describe |
|---|---|
| last | 最近一次的探测延迟值 |
| avg | 探测延迟的平均值 |
| best | 探测延迟的最小值 |
| wrst | 探测延迟的最大值 |
| stdev | 标准偏差。越大说明相应节点越不稳定 |
丢包判断
任一节点的 Loss%(丢包率)如果不为零,则说明这一跳网络可能存在问题。导致相应节点丢包的原因通常有两种。
- 运营商基于安全或性能需求,人为限制了节点的ICMP发送速率,导致丢包。
- 节点确实存在异常,导致丢包。可以结合异常节点及其后续节点的丢包情况,来判定丢包原因。
Notes:
- 如果随后节点均没有丢包,则通常说明异常节点丢包是由于运营商策略限制所致。可以忽略相关丢包。
- 如果随后节点也出现丢包,则通常说明节点确实存在网络异常,导致丢包。对于这种情况,如果异常节点及其后续节点连续出现丢包,而且各节点的丢包率不同,则通常以最后几跳的丢包率为准。如链路测试在第5、6、7跳均出现了丢包。最终丢包情况以第7跳作为参考。
延迟判断
由于链路抖动或其它因素的影响,节点的 Best 和 Worst 值可能相差很大。而 Avg(平均值)统计了自链路测试以来所有探测的平均值,所以能更好的反应出相应节点的网络质量。而 StDev(标准偏差值)越高,则说明数据包在相应节点的延时值越不相同(越离散)。所以标准偏差值可用于协助判断 Avg 是否真实反应了相应节点的网络质量。例如,如果标准偏差很大,说明数据包的延迟是不确定的。可能某些数据包延迟很小(例如:25ms),而另一些延迟却很大(例如:350ms),但最终得到的平均延迟反而可能是正常的。所以此时 Avg 并不能很好的反应出实际的网络质量情况。
这就需要结合如下情况进行判断:
- 如果 StDev 很高,则同步观察相应节点的 Best 和 wrst,来判断相应节点是否存在异常。
- 如果StDev 不高,则通过Avg来判断相应节点是否存在异常。
Tips:对于更多的网络工具的使用可以参考这篇文章
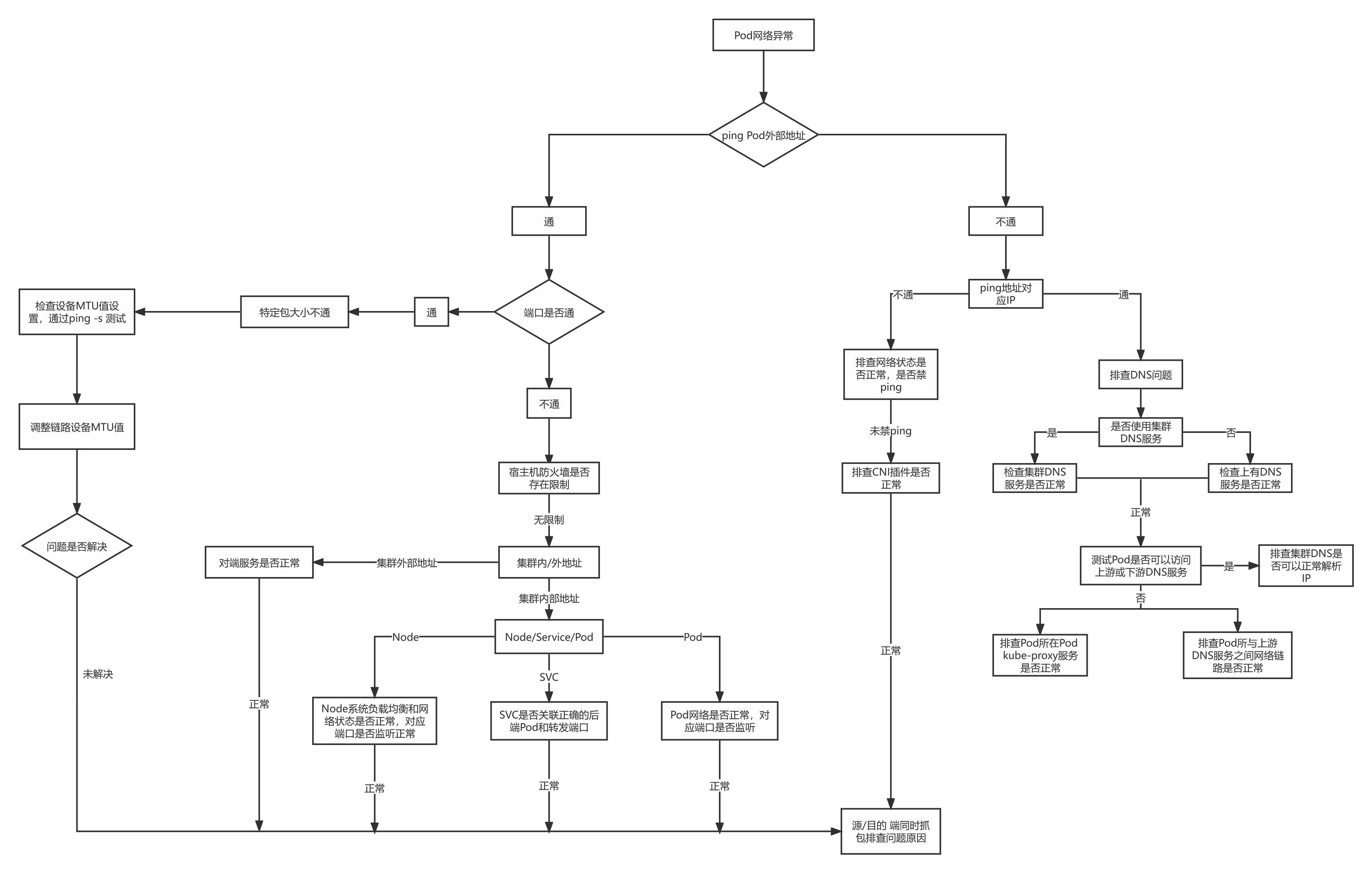
Pod网络排查流程
Pod网络异常时排查思路,可以按照下图所示
案例学习
扩容节点访问service地址不通
测试环境k8s节点扩容后无法访问集群clusterlP类型的registry服务
环境信息:
| IP | Hostname | role |
|---|---|---|
| 10.153.204.15 | yxxx-xxx-xxxfu12 | worknode节点(本次扩容的问题节点) |
| 10.153.203.14 | yxxx-xxx-xxxxfu31 | master节点 |
| 10.61.187.42 | yxxx-xxx-xxxxxxxxf8e9 | master节点 |
| 10.61.187.48 | yxxx-xxx-xxxxxx61e25 | master节点(本次registry服务pod所在 节点) |
-
cni插件:flannel vxlan
-
kube-proxy工作模式为iptables
-
registry服务
- 单实例部署在10.61.187.48:5000
- Pod IP:10.233.65.46,
- Cluster IP:10.233.0.100
现象:
-
所有节点之间的pod通信正常
-
任意节点和Pod curl registry的Pod 的 IP:5000 均可以连通
-
新扩容节点10.153.204.15 curl registry服务的 Cluster lP 10.233.0.100:5000不通,其他节点curl均可以连通
分析思路:
-
根据现象1可以初步判断 CNI 插件无异常
-
根据现象2可以判断 registry 的 Pod 无异常
-
根据现象3可以判断 registry 的 service 异常的可能性不大,可能是新扩容节点访问 registry 的 service 存在异常
怀疑方向:
- 问题节点的kube-proxy存在异常
- 问题节点的iptables规则存在异常
- 问题节点到service的网络层面存在异常
排查过程:
- 排查问题节点的
kube-proxy - 执行
kubectl get pod -owide -nkube-system l grep kube-proxy查看 kube-proxy Pod的状态,问题节点上的 kube-proxy Pod为 running 状态 - 执行
kubecti logs <nodename> <kube-proxy pod name> -nkube-system查看问题节点 kube-proxy的Pod日志,没有异常报错 - 在问题节点操作系统上执行
iptables -S -t nat查看iptables规则
排查过程:
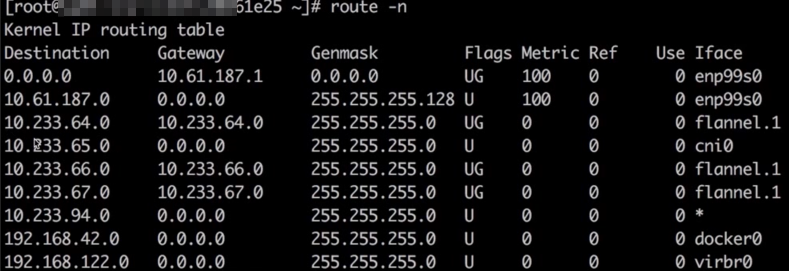
确认存在到 registry 服务的 Cluster lP 10.233.0.100 的 KUBE-SERVICES 链,跳转至 KUBE-SVC-* 链做负载均衡,再跳转至 KUBE-SEP-* 链通过 DNAT 替换为服务后端Pod的IP 10.233.65.46。因此判断iptables规则无异常执行route-n查看问题节点存在访问10.233.65.46所在网段的路由,如图所示
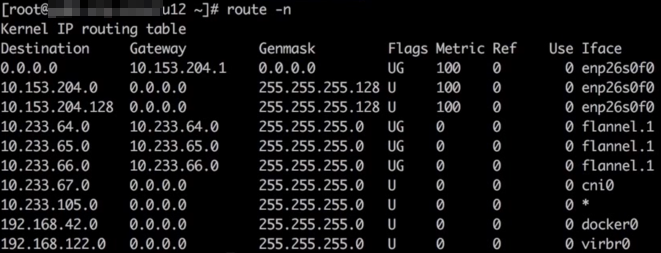
查看对端的回程路由
以上排查证明问题原因不是 cni 插件或者 kube-proxy 异常导致,因此需要在访问链路上抓包,判断问题原因、问题节点执行 curl 10.233.0.100:5000,在问题节点和后端pod所在节点的flannel.1上同时抓包发包节点一直在重传,Cluster lP已 DNAT 转换为后端Pod IP,如图所示

后端Pod( registry 服务)所在节点的 flannel.1 上未抓到任何数据包,如图所示

请求 service 的 ClusterlP 时,在两端物理机网卡抓包,发包端如图所示,封装的源端节点IP是10.153.204.15,但一直在重传

收包端收到了包,但未回包,如图所示

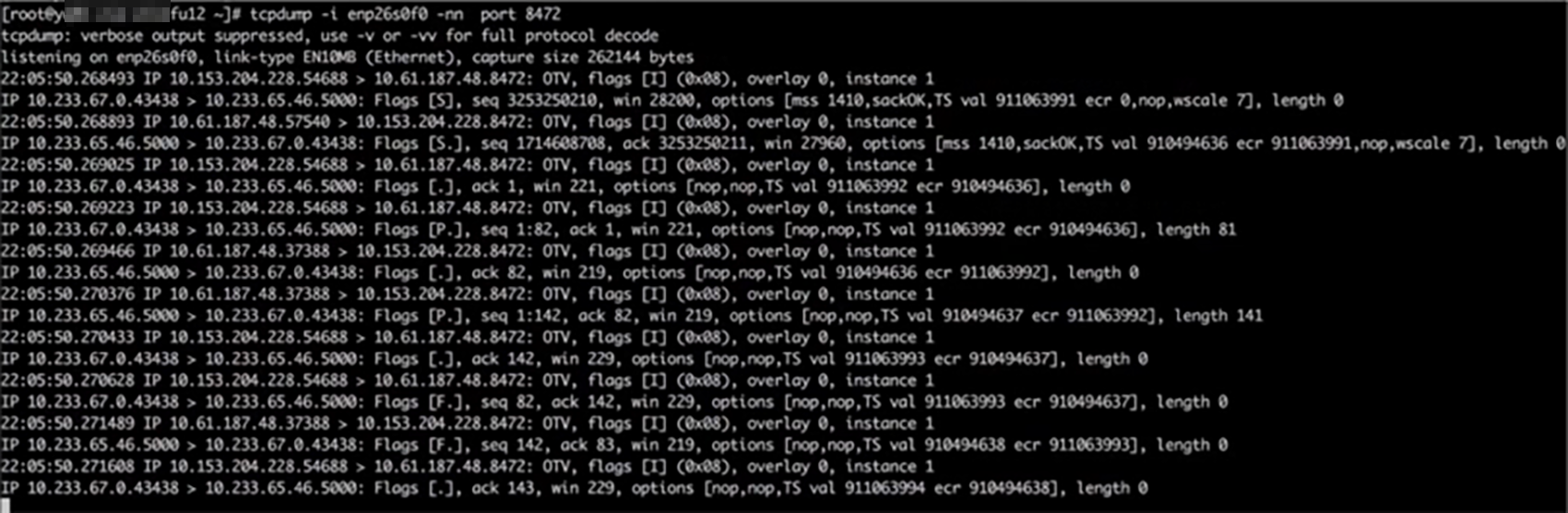
由此可以知道,NAT的动作已经完成,而只是后端Pod( registry 服务)没有回包,接下来在问题节点执行 curl 10.233.65.46:5000,在问题节点和后端( registry 服务)Pod所在节点的 flannel.1 上同时抓包,两节点收发正常,发包如图所示


接下来在两端物理机网卡接口抓包,因为数据包通过物理机网卡会进行 vxlan 封装,需要抓 vxlan 设备的8472端口,发包端如图所示
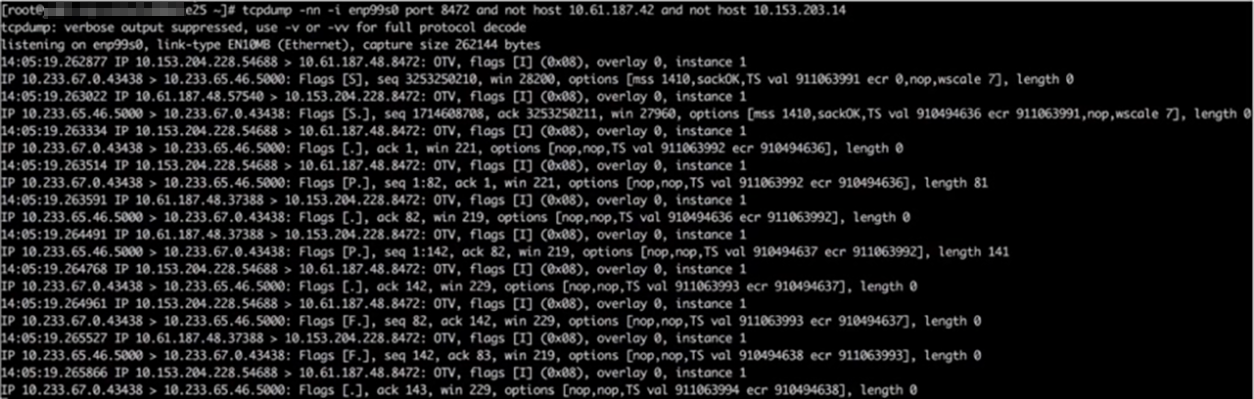
发现网络链路连通,==但封装的IP不对==,封装的源端节点IP是10.153.204.228,但是存在问题节点的IP是10.153.204.15
后端Pod所在节点的物理网卡上抓包,注意需要过滤其他正常节点的请求包,如图所示;发现收到的数据包,源地址是10.153.204.228,但是问题节点的IP是10.153.204.15。
此时问题以及清楚了,是一个Pod存在两个IP,导致发包和回包时无法通过隧道设备找到对端的接口,所以发可以收到,但不能回。
问题节点执行ip addr,发现网卡 enp26s0f0上配置了两个IP,如图所示
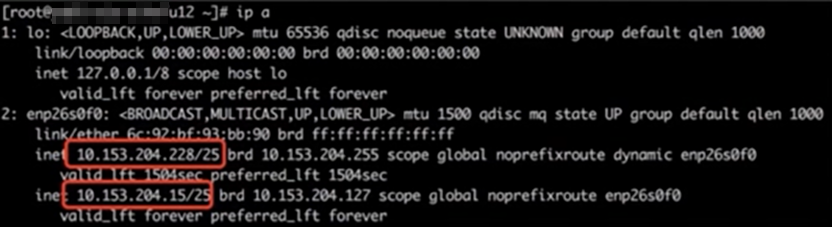
进一步查看网卡配置文件,发现网卡既配置了静态IP,又配置了dhcp动态获取IP。如图所示
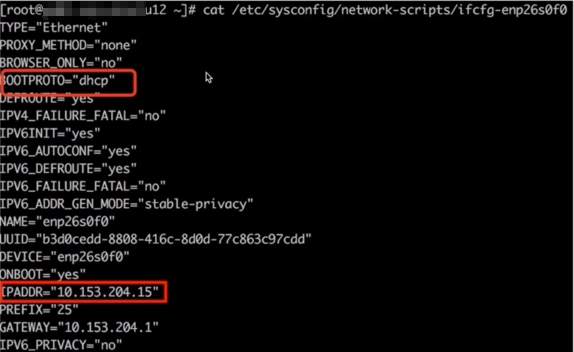
最终定位原因为问题节点既配置了dhcp 获取IP,又配置了静态IP,导致IP冲突,引发网络异常
解决方法:修改网卡配置文件 /etc/sysconfig/network-scripts/ifcfg-enp26s0f0 里 BOOTPROTO="dhcp"
为 BOOTPROTO="none";重启 docker 和 kubelet 问题解决。
集群外云主机调用集群内应用超时
问题现象:Kubernetes 集群外云主机以 http post 方式访问Kubernetes 集群应用接口超时
环境信息:Kubernetes 集群:calicoIP-IP模式,应用接口以nodeport方式对外提供服务
客户端:Kubernetes 集群之外的云主机
排查过程:
-
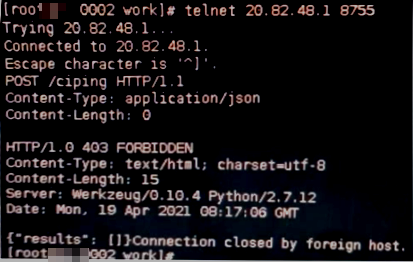
在云主机telnet应用接口地址和端口,可以连通,证明网络连通正常,如图所示
-
云主机上调用接口不通,在云主机和Pod所在 Kubernetes节点同时抓包,使用wireshark分析数据包
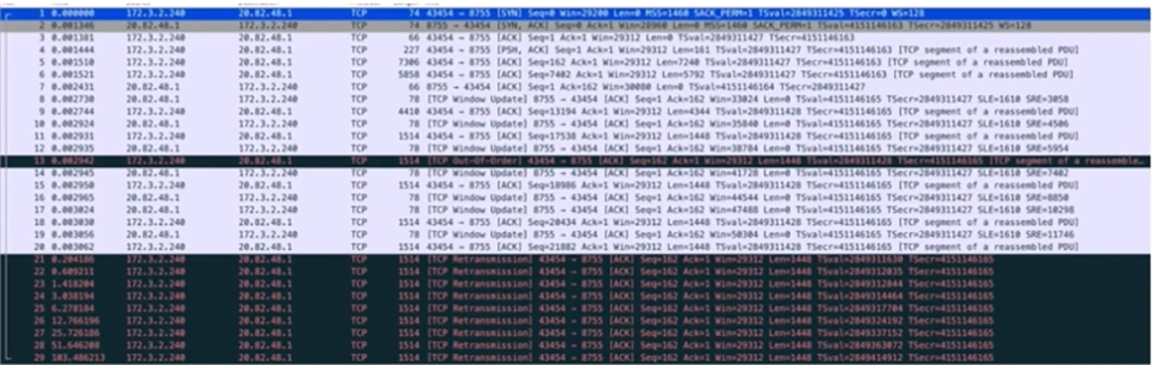
通过抓包结果分析结果为TCP链接建立没有问题,但是在传输大数据的时候会一直重传 **1514 **大小的第一个数据包直至超时。怀疑是链路两端MTU大小不一致导致(现象:某一个固定大小的包一直超时的情况)。如图所示,1514大小的包一直在重传。
报文1-3 TCP三次握手正常
报文1 info中MSS字段可以看到MSS协商为1460,MTU=1460+20bytes(IP包头)+20bytes(TCP包头)=1500
报文7 k8s主机确认了包4的数据包,但是后续再没有对数据的ACK
报文21-29 可以看到云主机一直在发送后面的数据,但是没有收到k8s节点的ACK,结合pod未收到任何报文,表明是k8s节点和POD通信出现了问题。
在云主机上使用 ping -s 指定数据包大小,发现超过1400大小的数据包无法正常发送。结合以上情况,定位是云主机网卡配置的MTU是1500,tunl0 配置的MTU是1440,导致大数据包无法发送至 tunl0 ,因此Pod没有收到报文,接口调用失败。
解决方法:修改云主机网卡MTU值为1440,或者修改calico的MTU值为1500,保持链路两端MTU值一致。
集群pod访问对象存储超时
环境信息:公有云环境,Kubernetes 集群节点和对象存储在同一私有网络下,网络链路无防火墙限制k8s集群开启了节点自动弹缩(CA)和Pod自动弹缩(HPA),通过域名访问对象存储,Pod使用集群DNS服务,集群DNS服务配置了用户自建上游DNS服务器
排查过程:
-
使用nsenter工具进入pod容器网络命名空间测试,ping对象存储域名不通,报错unknown server name,ping对象存储lP可以连通。
-
telnet对象存储80/443端口可以连通。 -
paping对象存储 80/443 端口无丢包。 -
为了验证Pod创建好以后的初始阶段网络连通性,将以上测试动作写入dockerfile,重新生成容器镜像并创pod,测试结果一致。
通过上述步骤,判断Pod网络连通性无异常,超时原因为域名解析失败,怀疑问题如下:
- 集群DNS服务存在异常
- 上游DNS服务存在异常
- 集群DNS服务与上游DNS通讯异常
- pod访问集群DNS服务异常
根据上述方向排查,集群DNS服务状态正常,无报错。测试Pod分别使用集群DNS服务和上游DNS服务解析域名,前者解析失败,后者解析成功。至此,证明上游DNS服务正常,并且集群DNS服务日志中没有与上游DNS通讯超时的报错。定位到的问题:==Pod访问集群DNS服务超时==
此时发现,出现问题的Pod集中在新弹出的 Kubernetes 节点上。这些节点的 kube-proxy Pod状态全部为pending,没有正常调度到节点上。因此导致该节点上其他Pod无法访问包括 dns 在内的所有Kubernetes service。
再进一步排查发现 kube-proxy Pod没有配置priorityclass为最高优先级,导致节点资源紧张时为了将高优先级的应用Pod调度到该节点,将原本已运行在该节点的kube-proxy驱逐。
解决方法:将 kube-proxy 设置 priorityclass 值为 system-node-critical 最高优先级,同时建议应用Pod配置就绪探针,测试可以正常连通对象存储域名后再分配任务。
Reference
[1] A tcpdump Tutorial with Examples
[3] man nsenter
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2022/08/pod-network-troubleshooting/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。