本文发布于Cylon的收藏册,转载请著名原文链接~
Overview
在编写程序时包含任意指令如,已初始化和未初始化数据,局部变量,函数等都是用于动态分配内存的指令。当程序编译后(默认生成 x.out 文件)这是一个可执行的链接文件( Executable and linking format)。在执行时这些不组织成几部分,包含不同的内存分段 (segments)
ELF:这是系统中标准二进制格式,其一些功能包含,动态链接,动态加载,对程序运行时控制。
可以使用 size {ELF_file} 查看被分配的每个段的大小(Linux操作系统);
dec列给出的是这个程序 text + data + bss 段的总大小,用十进制表示text段是存储可执行命令的段data段包含所有初始化数据,全局与静态变量BSS段包含未初始化数据
$ size 1
text data bss dec hex filename
1843 584 8 2435 983 1
Memory Layout in C [1]
在C语言中内存布局模型包含六个部分
- 命令行参数 (Command Line Arguments)
- 栈 (Stack)
- 堆 (Heap)
- 未初始化数据段 (Uninitialized Data Segment BSS)
- 已初始化数据段 (Initialized Data Segment)
- 文本/代码段 (Text/Code Segment)
这6部分结构可以再划分为两种类型:
- 静态内存结构 (Static Memory Layout):包含代码段, 数据段
- 动态内存结构 (Dynamic Memory Layout):包含栈, 堆
通过Overview中可以看到可以执行文件包含一些段,而缺少一些段,这部分是由运行时构建出来的。
整个C程序的内存布局为下图所示
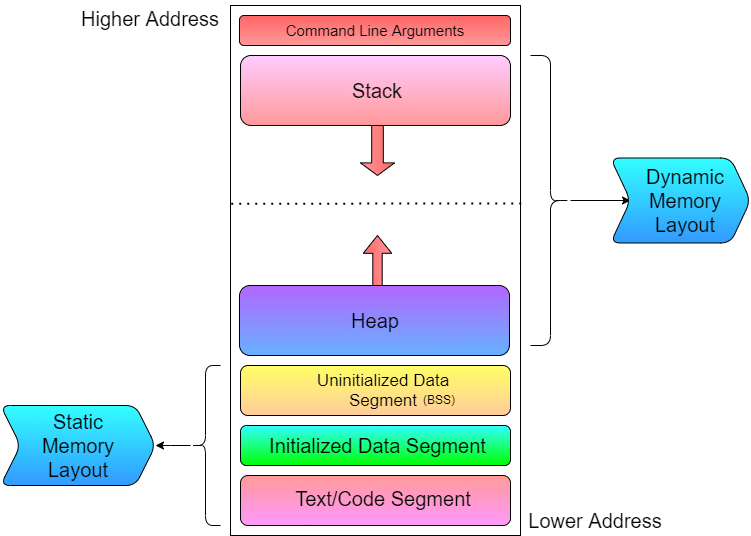
静态内存布局
静态内存布局中,包含代码段(Code Segment),数据段(Data Segment);数据段中又分为已初始化段,通常称为数据分段(DS),未初始化分段(BSS)。
代码段
代码段包含可执行的机器指令,这部分包含了程序的逻辑,为了防止堆, 栈的溢出,代码段在内存结构中处于布局中最下方。而且为了防止指令被修改,这部分是只读的。
- 已编译二进制文件
- 只读段,防止程序被修改
- 可共享
可以通过 objdump -S <file> 来导出代码段中存的汇编代码
已初始化数据段
所有已初始化的静态变量和全局变量都被存储在DS中,该段具有写权限,程序可以在运行时修改该段中变量的值。
定义一个C程序,通过size观看其data段的大小
#include <stdio.h>
char main()
{
return '1';
}
size输出为528
$ size 1
text data bss dec hex filename
1358 528 8 1894 766 1
通过增加两个变量,一个全局变量一个静态变量,观看编译后可执行文件data段的大小与之前大小相比较
#include <stdio.h>
static int a = 10; // int 类型占4byte
char b = 'a'; // char 类型占1byte
char main()
{
return '1';
}
size查看data输出值为533 与之前 528 增加 5 bytes,与定义的类型相符合
size 1
text data bss dec hex filename
1358 533 3 1894 766 1
未初始化数据段
未初始化数据段包含如下内容
- 未初始化的全局和静态变量
- 初始化为0或空指针的变量
接着上述例子,添加两个变量,一个不初始化值,一个初始化为0
#include <stdio.h>
int a;
static int b=0;
char main()
{
return '1';
}
通过 size 命令可以看出,这些都被分配到 BSS 部分
$ size 1
text data bss dec hex filename
1358 528 16 1902 76e 1
对于初始化段与未初始化段和只读数据段 (.rodata) 都会被分配到数据段中
动态内存布局
动态内存是指程序运行时创建的的内存
heap
堆段是由BSS往上更高部分动态内存分配的段,heap段具有以下特点
-
程序运行可以没有heap段
-
heap位于在BSS之上stack之下,与stack成反方向增长和减少
-
运行时分配内存
-
由函数
malloc(),calloc(),free()等函数管理 -
heap段内存由进程中共享库和动态模块等共享内存
heap对于stack来说,最大的特点就是没有自动的内存管理功能,所有内存的申请和销毁都是通过开发者自行定义的,C中的Glibc API 提供了申请和销毁heap内存的功能。
- 函数
malloc()/calloc()用户空间实现的库函数,用于申请heap内存,可用于windows/linux - 函数
free()释放由malloc()/calloc()申请的内存 brk()/sbrk()是linux下的系统调用,在内核空间实现的库函数
下列代码为heap内存分配示例
#include <stdio.h>
#include <stdlib.h>
int func()
{
int a = 10;
int *aptr = &a;
int *ptr = (int *)malloc(sizeof(int));
*ptr = 20;
printf("Heap Memory Value = %d\n", *ptr);
printf("Pointing in Stack = %d\n", *aptr);
free(ptr);
}
int main()
{
func();
return 0;
}
下图为上述代码的图形化布局,通过申明一个指针变量 *ptr 指向了通过函数 malloc() 申请的 heap内存
Notes: heap变量的存储实际存储时在物理内存上,而heap,stack.. 都是虚拟内存中某个进程的地址空间,通过MMU将其转为物理地址进行读写。[2]
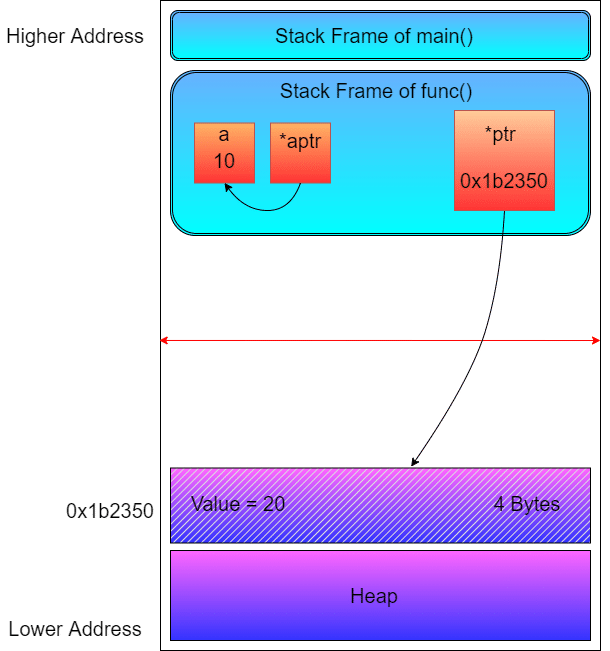
stack
stack是与heap相邻的地区,并与heap以反方向增长,当遇到heap时表示可用内存耗尽。stack段具有如下特点:
- 程序运行必须拥有的内存段
- 以先进先出 (LIFO) 的顺序添加和移除数据
- 包含以下内容
- 所有局部变量
- 函数参数(逆序)
- 函数调用的返回地址
- 基于指针的函数调用
- stack段自动分配和销毁内存,开发者无法控制stack段内存
- 当函数执行完函数局部变量会从stack中弹出释放,也就是局部变量的作用域范围
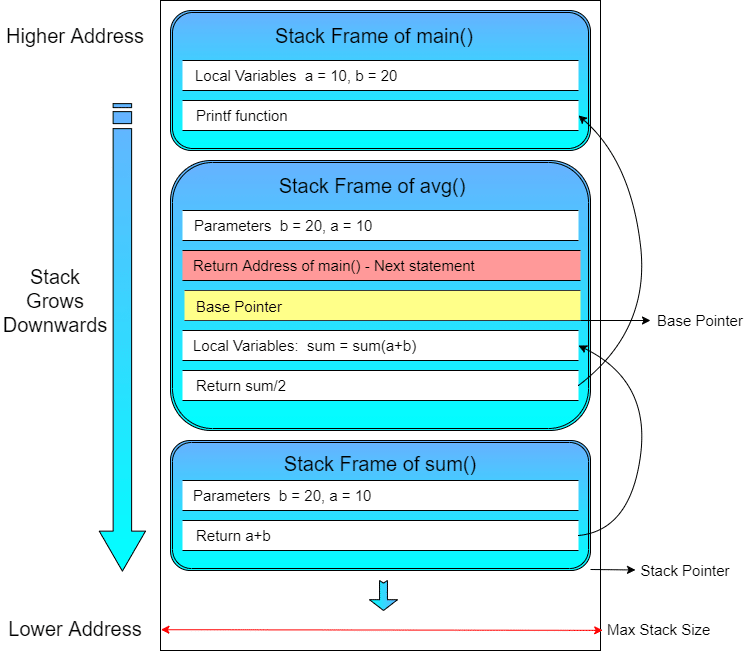
例如
#include
int sum(int a, int b)
{
return a + b;
}
float avg(int a, int b)
{
int s = sum(a, b);
return (float)s / 2;
}
int main()
{
int a = 10;
int b = 20;
printf("Average of %d, %d = %f\n", a, b, avg(a, b));
return 0;
}
下图是上述代码对于stack内存段执行时的说明,如图所示,整个如下:
- 当main函数被执行时会被压入stack中
- main函数会调用avg函数求平均值,此时avg被压入stack
- avg执行sum函数,sum被压入stack
- 此时正在执行的帧时位于最顶层的,被称为基指针 (base pointer)
- 栈帧指向stack段顶部,存储stack最顶部地址
- s是一个指针保存着sum的位置,即sum函数的结尾,依次类推
栈异常
栈异常常见异常情况有
- 栈溢出 (Stack Overflow):栈溢出是指超出stack的大小,例如很长的函数调用,造成该错误原因如下:
- 递归函数调用
- 大数据声明
- 栈毁坏 (Stack Corruption):是指stack段中的某些内存位置由于错误的编码而被无意访问,导致内存位置发生变化。由于数据毁坏位置发生在Stack段因此被称为 “Stack Corruption” [4]
例如下面代码模拟了一个 SC 异常
#include <stdio.h>
#include <string.h>
int copy(char *argv)
{
char name[10];
strcpy(name, argv);
}
int main(int argc, char **argv)
{
copy(argv[1]);
printf("Exit\n");
return 0;
}
输出结果为:可以看到当char大小大于10,会覆盖其他stack位置,使程序无法继续执行从而输出“Exit”。
$ gcc .\1.c -o 1.exe
$ .\1.exe testargs
Exit
$ .\1.exe testargs000000000000000000
Stack VS Heap [3]
- Stack与Heap都存储与RAM中
- Stack自动管理内存,而Heap则需要手动申请和取消
- Stack分配速度快(一段程序启动时预先分配好的连续内存),而Heap分配速度较慢(动态分配的非连续内存)
- Stack在使用是会出现溢出问题,而Heap可以分配大数据
- Stack常见错误为内存溢出,Heap常见错误为内存泄漏
Stack 和 Heap 的一些常见问题
- 默认Stack大小为多少:Linux中通过
ulimit -s可以查看 - 默认的Heap大小为多少:没有默认的Heap大小,在32位操作系统中,每个进程可以看到连续的4GB空间,这个空间没有被映射到物理地址中,而是根据使用情况进行映射,在64位操作系统中,这个空间会更大
- stack和heap存放在哪里?:在虚拟内存中,通过MMU进行映射到物理地址上
- 如何手动配置heap?:可以使用
ulimit -v设置虚拟内存的大小
函数调用栈
函数调用与栈有不可密切的关系,在一个函数调用过程所需要的信息一般包括以下几个方面:
- 函数返回地址
- 函数参数
- 变量
- 保存的上下文 :包括在函数调用前后需要保持不变的寄存器。
当在调用一个函数时,控制流从调用函数转移到被调用函数。如下列代码在运行时产生了如下几项疑问:
- 函数参数和用于调用函数的变量的区别
- 为什么具有多个相同名称但位于不同函数中的变量可以共存?
- 为什么函数doing有一定的限制?
- 为什么未初始化的局部变量可能包含任何值?
#include <stdio.h>
int mogrify(int a, int b){
int tmp = a*4 - b / 3;
return tmp; // (mogrify函数返回值)
}
double truly_half(int x){
double tmp = x / 2.0;
return tmp;
}
int main(){
int a = 7, y = 17;
int mog = mogrify(a,y); // 调用mogrify
printf("Done with mogrify\n");
double x = truly_half(y); // 调用truly_half
printf("Done with truly_half\n");
a = mogrify(x, mog); // 第二次调用mogrify
printf("Results: %d %lf\n",mog,x); // (last_print)
return 0; // (main函数返回)
}
输出
lila [stack-demo-code]% gcc simple_calls.c
lila [stack-demo-code]% ./a.out
Done with mogrify
Done with truly_half
Results: 23 8.500000
栈行为 [4]
-
main函数的调用
上述代码调用stack发生的变化,程序从第一行的 main() 函数开始。 main() 有 3 个局部变量:a,y 是int,x 是double。栈的初始状态如下表(其中地址栏为虚构地址)
Method Line Var Value Addr Notes main() 12行开始 a ? 1024 y ? 1028 mod ? 1032 x ? 1036 表1
-
main函数的第一行被执行
在运行 main(从第 12 行开始)时,会为所有局部变量分配了栈空间,但没有定义值(随机被初始化)在向下移动时,为局部变量a,y 定义了值。
Method Line Var Value Addr Notes main() 13行 a 7 1024 y 17 1028 mod ? 1032 x ? 1036 表2
-
mogrify()被调用 在第13行时产生一个函数调用,main函数被暂停,至函数 mogrify 完成。函数调用使一个栈push到调用栈,如下表所示。
Method Line Var Value Addr Notes main() 13行 a 7 1024 y 17 1028 mod ? 1032 x ? 1036 mogrify() 4行 a 7 1044 b 17 1048 tmp ? 1052 表3
-
mogrify()第一行被执行 此时从 mogrify 的第一行开始,完成后返回至 main 函数,将在第 13 行继续执行。表3中由于没有执行到tmp,所以还没被分配值。
表4是 完成mogrify 函数执行,局部变量 tmp 被赋值。
Method Line Var Value Addr Notes main() 13行 a 7 1024 y 17 1028 mod ? 1032 x ? 1036 mogrify() 5行 a 7 1044 b 17 1048 tmp 23 1052 表4
-
mogrify()函数返回
mogrify函数返回在这里有两个作用:
- 返回值被存储在调用函数位置:main函数 (第 13 行)变量 mog 中。
- 弹出栈帧,从调用堆栈中移除。
此时状态为表5
Method Line Var Value Addr Notes main() 14 a 7 1024 y 17 1028 mod 23 1032 x ? 1036 表5
-
执行Printf()
Method Line Var Value Addr Notes main() 13行 a 7 1024 y 17 1028 mod ? 1032 x ? 1036 printf() lib call format ? 1044 pointer 表6
printf()也是作为函数,将另一个栈帧推入栈中,并为其参数和局部变量预留空间。 printf()是一个可变参数的函数。
-
第二次函数调用
从第 16 行起,调用了函数
truly_half此时会将一个栈帧推入调用栈。此时状态如表5相同 -
调用函数truly_half()
当函数
truly_half()被调用,对应的栈帧被push到main的栈帧下,表7中所示的地址(局部变量)与之前mogrify()函数是相同的地址,这是因为栈中的空间是可重用的。Method Line Var Value Addr Notes main() 16 a 7 1024 y 17 1028 mog 23 1032 x ? 1036 truly_half()8 x 17 1044 tmp ? 1048 表7
-
truly_half()被执行
执行
truly_half函数的第二行返回计算后的值来赋值给 main 中的局部变量 x,并从调用栈中弹出truly_half的栈帧,如表8所示Method Line Var Value Addr Notes main() 16 a 7 1024 y 17 1028 mog 23 1032 x ? 1036 truly_half()9 x 17 1044 tmp 8.5 1048 表8
-
返回main函数控制流
main函数中会打印这个值,此时内存结构为表8所示
Method Line Var Value Addr Notes main() 17 a 7 1024 y 17 1028 mog 23 1032 x 8.5 1036 表9
-
再次调用函数mogrify()
此时,main函数在第19行暂停,在
mogrify()第一行开始。需要注意的一点是
mogrify()参数类型是int,这里会强制转换 8 字节double 为一个 4 字节的int,小数点被省去。如表10所示Method Line Var Value Addr Notes main() 19 a 7 1024 y 17 1028 mog 23 1032 x 8.5 1036 double mogrify() 4 a 8 1044 convert to int b 23 1048 tmp ? 1052 表10
-
mogrify()被执行后:
Method Line Var Value Addr Notes main() 19 a 7 1024 y 17 1028 mog 23 1032 x 8.5 1036 double mogrify() 5 a 8 1044 convert to int b 23 1048 tmp 25 1052 表11
-
mogrify()被执行后:
mogrify()执行完成后将结果分配给 main 函数中的局部变量 a 并弹出栈帧。此时数据如表12所示Method Line Var Value Addr Notes main() 19 a 25 1024 a的值被覆盖 y 17 1028 mog 23 1032 x 8.5 1036 double 表12
至此返回最开始的部分,一个函数的过程包含四个部分 (function call stack)
- 函数调用栈
- 动态分配内存区域 (heap)
- 存储全局变量的区域
- 程序允许的实际代码(data text)
栈帧(stack frame) 指的是:栈内存中单个函数调用(正在允许的函数)的一部分内存块,(参数和局部变量)。编译器在编译期间确定函数的栈帧大小。栈上的栈帧通常与尚未返回的函数一样多。
栈行为:
- pushing :当函数被调用时,新的帧被推到调用堆栈的 “顶部”。
- popping:当函数执行完成,会将控制权返回给调用它的函数。并将函数关联的帧从栈顶部弹出。
溢出:如果在返回之前调用了太多函数(例如递归),程序可能会耗尽栈空间。
关于栈的总结
C语言的执行模型
- C 语言是过程式编程,不支持在函数之外编写代码
- C 语言的执行模型是指函数调用工作原理(函数调用栈行为分析的)及函数工作原理。
- C 语言使用 ”栈“ 数据结构来实现函数与函数调用。
关于函数调用栈
-
函数调用栈是动态数据结构,用于参数传递、局部变量分配、保存调用的返回地址、保存寄存器以供恢复。
-
栈向下增长,从较高的地址开始,向较低的地址。
-
Push 将栈帧添加到栈,Pop从栈中弹出
-
栈帧的增长在x86架构下是4字节:
- 假设栈指位于1000,此时push一个函数,则该栈指指向996(1000 - 4)
- 假设此时弹出函数,那么会从996处从栈中弹出,并递增并指向地址1000
调用惯例 [6]
调用惯例 (Calling Conventions) 是指函数调用的标准化方法,当在函数调用时例如,如何将参数传递给子程序?子程序可以覆盖寄存器中的值,还是调用者希望保留寄存器内容?子程序中的局部变量应该存储在哪里?函数应该如何返回结果?
C语言中调用惯例在很大程度上使用了基于硬件支持栈。对C中调用惯例的理解就需要对函数执行模型的理解(应确保完全理解 push、pop、call 和 ret 指令的行为)。在此调用约定中,子程序参数在stack上传递。寄存器保存在stack上,子程序使用的局部变量放在stack上的内存中。
-
cdecl (c declaration):C/C++默认调用约定,调用时按照从右向左的参数入
push arg3 ; rightmost argument push arg2 push arg1 ; leftmost argument call f add esp, 12 ; 12 = 3 arguments each being 4 bytes -
fastcall:通过寄存器传递值(从右到左)
-
thiscall:指针类型被存储在寄存器
ecx,其他类型放置堆栈
Reference
[2] stack and heap locations in ram
[3] what and where are the stack and heap
[4] understanding stack corruption c
[5] static
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2022/09/ch06-memory-layout/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。