本文发布于Cylon的收藏册,转载请著名原文链接~
背景
Prometheus 是目前云原生架构中监控解决方案中的基石,而对于 “metrics”,“traces” 和 “logs” 是组成云原生架构中“可观测性”的一个基础,当在扩展 Prometheus,那么 Prometheus 提供的基础架构是无法满足需求的(高可用性和可扩展性), 而高可用性与可扩展性是满足不断增长基础设施的一个基本条件。而 Prometheus 本身并没有提供“弹性”的集群配置,也就是说,多个副本的 Prometheus 实例,对于分布在每个 Pod 上的数据也会不一致,这时也需要保证指标的归档问题。
并且在一定的集群规模下,问题的出现远远大于 Prometheus 本身的能力,例如:
- 如何经济且搞笑的存储历史数据(TB, PB)?如何快速的查询历史数据?
- 如何合并 Promehtues 多个实例收集来的副本数据?
- 以及多集群间的监控?
- 由于 TSDB 的块同步,Prometheus 严重依赖内存,使得 Prometheus 监控项的扩展将导致集群中的CPU/MEM 的使用加大
- ..
解决
Thanos 是一款可以使 Prometheus 获得 ”长期存储“,并具体有”高可用性“ 的 Prometheus 的功能扩展,“Thanos” 源自希腊语“ Athanasios”,英文意思是”不朽“。这也正是 ”Thanos“ 提供的功能:”无限制的对象存储“,并与原生 Prometheus API 高度兼容,你可以理解为 Thanos API 就是 Prometheus API。
Cortexmetrics 与 Thanos 类似,是用通过将 Prometheus 实例的”存储“和”查询“等功能分离到独立的组件中,实现水平扩展。它使用对象存储来持久化历史指标,块存储(TSDB)是他的存储后端;此外,Cortex 还提供了多租户与多租户隔离等功能
联邦集群,联邦集群是 Prometheus 官方提供的一个概念,使用了联邦将允许 Prometheus 从另一个 Prometheus 中抓取选定的指标。可以使用的一些模型如下:
- 分层联邦:大规模的集群中,Prometheus 部署模型如一个”树形“,高级别的从多个低级实例中抓取指标,并存储聚合
- 跨服务联邦:Prometheus 从另一个 Prometheus 只抓取指定的数据
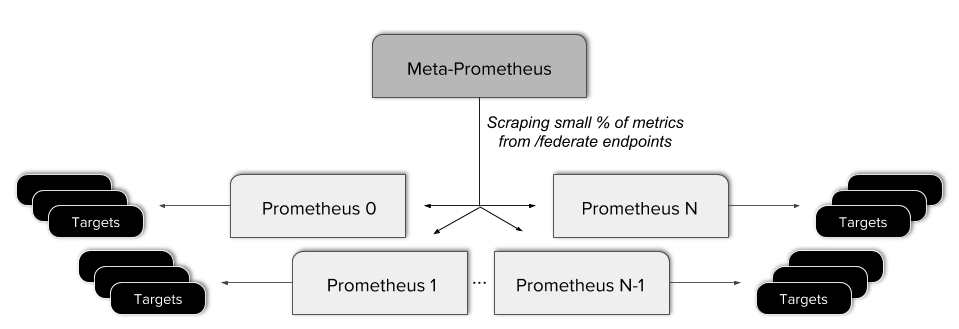
但在这种架构中,仍然还是每个查询只能针对单个 Prometheus 服务器完成。另外 Thanos 可以查询与聚合来自多个 Prometheus 实例的数据,这些数据就类似与联邦中的 ”叶“,这些数据的来源可以单实例也可以是多实例。
在这种架构中,本质上并不是 ”高可用性“ 的,实际上存在潜在故障点,并且数据的查询是通过唯一入口(API)进行查询,并且需要配置复杂的抓取规则才可以使规则不重复。
Thanos 架构
Thanos 遵循了 KISS (Keep it simple) 原则,thanos 由多个组件组成,每个组件负责不同的功能,
在与 Prometheus 交互方向,Thanos 使用下列两种方式(组件):
-
Sidecar:
- 连接到 Prometheus,读取数据或者将数据上传到对象存储中
- 也可以部署为传统架构,这里不能完全理解为是 Kubernetes 中的 Sidecar
-
Receiver:从 Prometheus 接收数据,暴露或上传到云端
扩展 Prometheus 的功能:
-
Store/Store Gateway:提供存储在对象存储中的历史数据的查询功能,历史 Chunk 会存储在对象存储中
- 支持基于 “时间/标签” 的分区
-
Compactor:对于存储在对象存储中的数据进行压缩,通过将其合并为更大的快,以便提高查询效率
-
Ruler/Rule:类似与 Alertmanager 的功能,他提供了告警功能
-
Querier/Query:实现了 Prometheus API,他可以从 Sidecar 与 对象存储中查询全局查询
-
Query Frontend:实现了 Prometheus API 并将请求代理至 Query 组件;并且支持缓存功能(Redis/Memcached),缓存其查询结果
Thanos 不是一种 “节省指标存储” 的方案,而是一种提供更大时间间隔,更高可用性的的查询方案,使用Thanos 不会减少磁盘空间,反而会增加磁盘空间。
通常 Thanos 会按照维度划分为三个级别:raw, 5m, 1h,这是根据时间划分,raw 是从 Prometheus 拿到的原始数据; 5m 压缩为5分钟的快;1h 压缩为 1h的块 [1] 。不过这些没有在官方找到,引用的其他文章
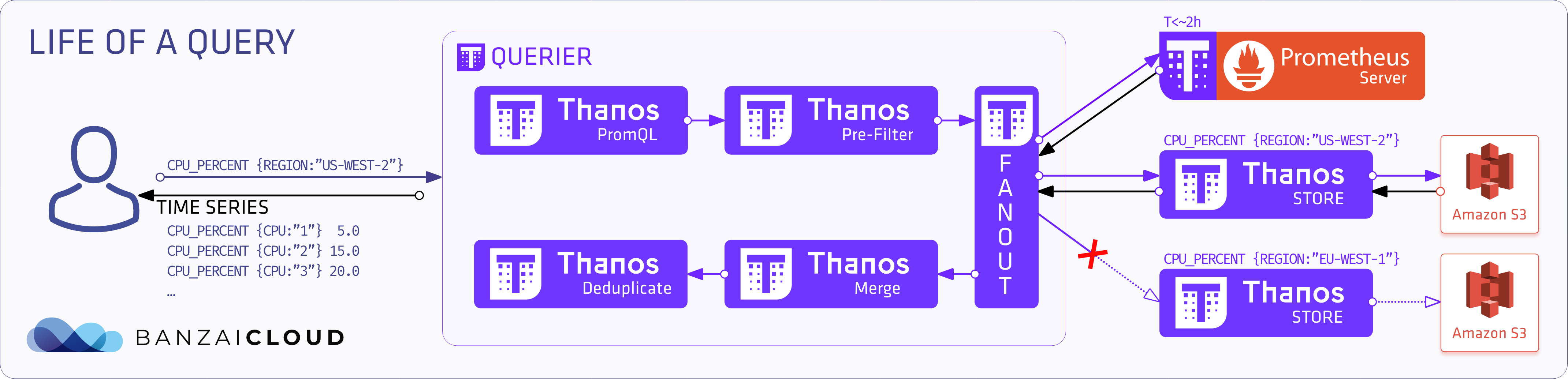
指标的查询过程
- PromQL 查询请求到组件
Querier - 它解释查询并进入预过滤器
- 查询根据标签和时间范围要求 扇出 (fan-out) 其对
stores或prometheuses的请求- store 决定 是否从s3中拉去数据
- query 会缓存数据到内存中
- Query 发送和接收请求
- 收集所有响应后,如果启用合并功能,会合并并删除重复数据
- 最后返回该时间序列
基于时间的分片
默认 Thanos 的 Store gateway 会查询对象中的所有存储,根据查询时间返回数据,这显然不行,如果此时有大量数据(基于PB级别),此时可以根据时间分片(水平扩展),Store API 可以使用 最大时间 和 最小时间 来缩短查询的时间,
基于标签的分片
基于标签的分片与基于时间的分片类似,这里是使用labels,而 Label 是采集与 Prometheus 的外部 Label ,并基于 Thanos 组件显式重新标记,要记住,Thanos 就是 Prometheus 扩展,功能用法与 Prometheus 是相同的的,例如下列 Thanos relabeling 的操作
- action: keep
regex: "eu.*"
source_labels:
- region
这些表示了只保留了以 eu.* 开头的 region label
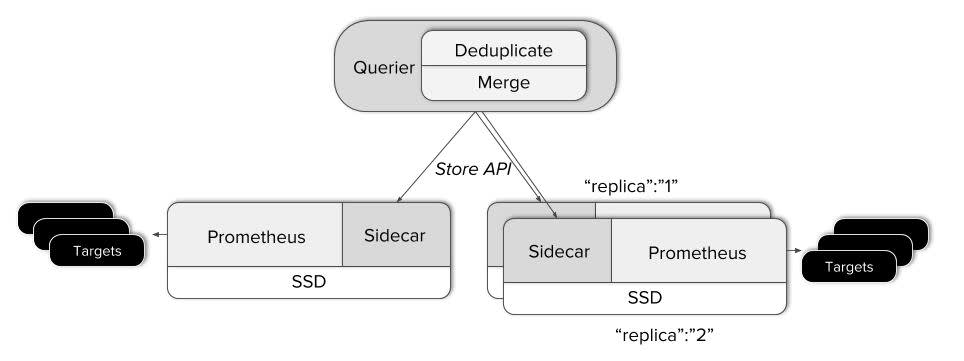
重复副本的删除
Thanos 对于 Prometheus 的 HA,也就是采集多个 Prometheus 实例的指标,此时 每个实例会产生相同的指标,这种模式来实现的“高可用性”,那么这种架构产生的重复副本就需要 Thanos 来处理了,例如如下所示:up{job="prometheus",env="2"} 的指标, 通过重复数据删除,结果是:
up{job="prometheus",env="2",cluster="1"} 1
up{job="prometheus",env="2",cluster="2"} 1
那么如果不删除重复标签,可能结果就很多,是用过 replica 标签来区分副本数量
up{job="prometheus",env="2",cluster="1",replica="A"} 1
up{job="prometheus",env="2",cluster="1",replica="B"} 1
up{job="prometheus",env="2",cluster="2",replica="A"} 1
up{job="prometheus",env="2",cluster="2",replica="B"} 1
全局视图查询
如图所示,query 是一种无状态的可水平扩展的 Querier 组件,他提供了基于 Prometheus API ,可以相应基于 PromQL 的查询,而中间数据的相应是由 Store 或者
高基数
基数 (cardinality) 通俗来说是一个集合中的元素数量 [1] 基数的来源通常为:
- label 的数量
- series(指标) 的数量
- 时间:label 或者 series 随时间而流失或增加,通常是增加
那么这么看来高基数就是,label, series, 时间这三个集合的笛卡尔积,那么高基数的情况就很正常了。
而高基数带来的则是 Prometheus 资源使用,以及监控的性能。下图是 Grafana Lab 提到的一张图,很好的阐述了高基数这个问题
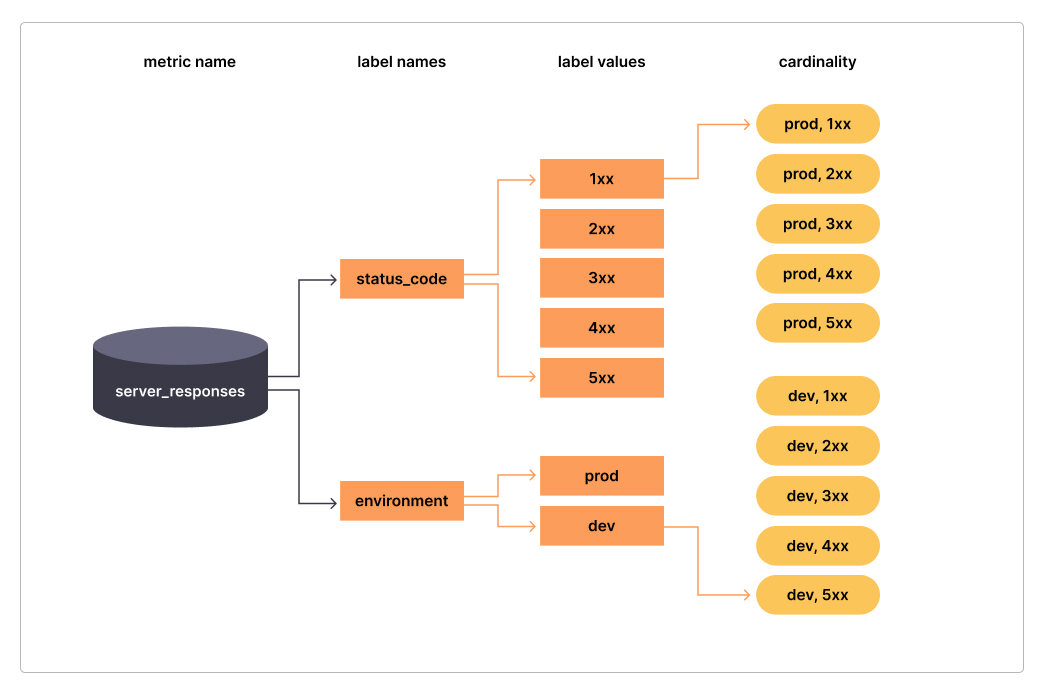
如图所示:一个指标 server_responses 他的 label 存在两个 status_code 与 environment ,这代表了一个集合,那他的 label value 是 1~5xx,这个指标的笛卡尔积就是10。
那么此时存在一个问题,如何能定位 基数高不高,Grafana Lab 给出了下面的数据 [1],但是我不清楚具体的来源或者如何得到的这些值。也就是 label:value
- 低基数:1: 5
- 标准基数:1: 80
- 高基数:1: 10000
为什么指标会指数级增长
在以 Kubernetes 为基础的架构中,随着抽象级别的提高(通常为Pod, Label, 以及更多抽象的拓扑),指标的时间序列也越来越多。因为在这种基础架构中,在传统架构中运行的一个应用的单个裸机,被许多运行分散在许多不同节点上的许多不同微服务的 Pod 所取代。在这些抽象层中的每一个都需要一个标签,以便可以唯一地标识它们,并且这些组件中的每一个都会生成自己的指标,从而创建其独特的时间序列集。
此外,在 Kubernetes 中的工作负载的短暂性最终也会创建更多的时间序列。例如 JAVA的 http_request_duration_seconds_bucket 指标,它会每次 pod 更改状态时生成一个新的时间序列,比如从“状态200" 或者 “状态 404” 在到 “每个URL” 再到 “每个请求的时间”,这样大量短时间请求,对一个 Pod 状态可能会生成大量指标。
这是就要考虑到 Prometheus 兼容的格式,而非传统监控的监控指标的格式问题,就例如上面的例子,通过对 URI,请求时长,请求状态码几个维度去监控,那么此时的 exporter 导出的数据势必是非常杂乱的,而这种可能相同的指标就会放大到无穷。
在这种环境中的 Label,就是两组集合的笛卡尔积的选择,就是次优标签 sub-optimal labels ,对付这类高基数的指标,控制基数,以及如何避免使用这类错误,就是解决高基数的根本。
高基数是一个非常重要的问题
高基数的问题,带来的就是基于 Prometheus 的监控带来的是更多的可观测性,反之,随着时间序列的基数增加,那么为了维持某几个特别的指标的观测性,就必须要付出更多的硬件资源,以及影响本身监控系统的性能。比较明显的表现,就是监控的相应下降,极大的拖慢了整个系统的运行速度(包含仪表盘,promQL等)。还会延长系统故障排除时的MTTR (Mean Time to Repair)。
Notes: 其实这里还有一类型错误,就是这会导致时间序列的乱序,怎么说呢,就是当指标无线放大时,在某一个点 scrap 的指标存储时间,大于了抓取周期,导致新指标存储早于旧指标,这种很容易出现在例如 Prometheus 的从内存到存储的那个点。
如何控制控制指标的高基数增长
指标的无序扩张(高基数)是不可避免对监控系统产生非常大的影响(存储和性能),而为此引出了一个如何优化不断增长的指标就是控制高基数增长的关键部分,下面将从几个维度来阐释控制“高基数”问题的步骤
第一步:高基数指标是否有价值?
在任何优化方法的第一步都是去了解哪些指标给系统带来负面影响(这里指高基数),并且还需要确定这些指标中哪些指标是有价值的;所谓的有价值既,在仪表板、告警中是否有被使用。
基于这些信息,我将根据基数问题与监控指标的价值分为四个象限:
- 高价值,低成本:闲置、陈旧、很长时间没有新数据的
- 低价值,低成本:基本上没有什么影响,但是需要去考虑优化
- 低价值,高成本:可以考虑删除掉 Label 和 metric
- 高价值,高成本:你的指标是否过细化,是否需要重新设计 Label 或者聚合数据;或这类指标是否适合使用 Prometheus 这类时间序列
第二步:如何确定高基数指标
确定高基数指标包含3种方式
- Prometheus WEB UI 分析,2.14 版本之后
- PromQL 分析
- Prometheus API 分析
通常情况下,WEB UI 就可以满足需求了,通过路径 Prometheus UI -> Status -> TSDB Status -> Head Cardinality Stats。
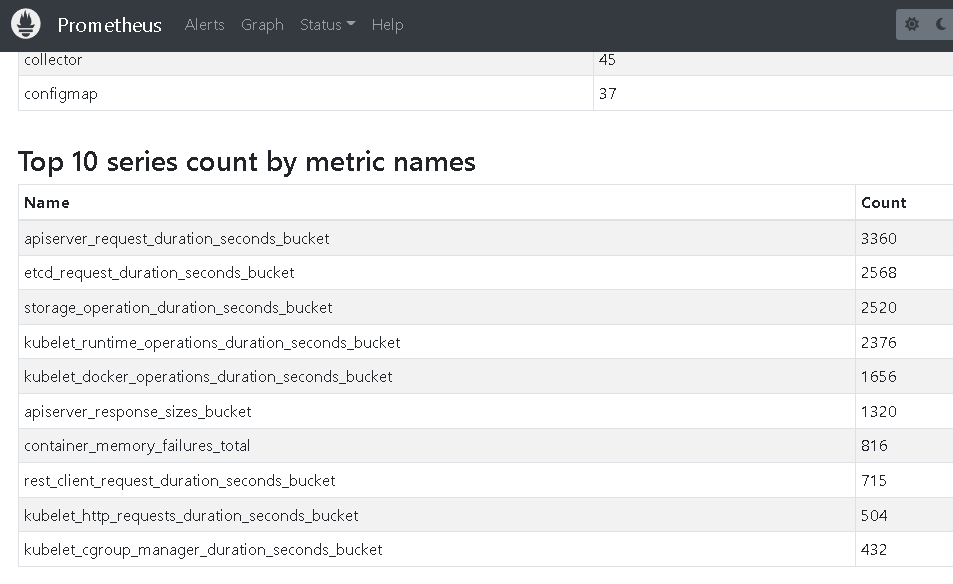
由上图可见,在这里体现的高基数问题的指标,通常都是以 bucket 结尾的指标,而这些指标通常包含2个维度,会无线拉长成为高基数指标。如下面指标所示,通常由 le (标识每个 bucket 的上限,这可以确保可以定位到在一个时间范围内相应的请求指标有哪些)
apiserver_request_duration_seconds_bucket{component="apiserver", endpoint="https", group="admissionregistration.k8s.io", instance="10.0.0.4:6443", job="apiserver", le="+Inf", namespace="default", resource="mutatingwebhookconfigurations", scope="cluster", service="kubernetes", verb="DELETE", version="v1"} 19
apiserver_request_duration_seconds_bucket{component="apiserver", endpoint="https", group="admissionregistration.k8s.io", instance="10.0.0.4:6443", job="apiserver", le="0.05", namespace="default", resource="mutatingwebhookconfigurations", scope="cluster", service="kubernetes", verb="POST", version="v1"}
apiserver_request_duration_seconds_bucket{component="apiserver", endpoint="https", group="admissionregistration.k8s.io", instance="10.0.0.4:6443", job="apiserver", le="0.25", namespace="default", resource="mutatingwebhookconfigurations", scope="cluster", service="kubernetes", verb="PATCH", version="v1"}
例如下面是生产环境中的一个高基数TOP10
| Name | Count |
|---|---|
| http_server_requests_seconds_bucket | 2017537 |
| lettuce_command_firstreponse_seconds_bucket | 755056 |
| lettuce_command_completion_seconds_bucket | 755056 |
| http_server_requests_seconds | 555575 |
| nginx_ingress_controller_request_duration_seconds_bucket | 475440 |
| node_ipvs_backend_connections_inactive | 148796 |
| node_ipvs_backend_connections_active | 148796 |
| apiserver_request_duration_seconds_bucket | 27896 |
| etcd_request_duration_seconds_bucket1 | 22763 |
至此可以看到实际上 http_server_requests_seconds_bucket 这一个指标占据了 prometheus 总指标的50%+
而其他的一些分析,可以很有效的定位到你需要优化的标签
- Top 10 label names with high memory usage
- Top 10 series count by label value pairs
通过 promQL 定位 job
- 查询 top 10 的 series
topk(10, count by (__name__)({__name__=~".+"})) sum(scrape_series_added) by (job)通过 job Label 分析 series 增长sum(scrape_samples_scraped) by (job)通过 job Label 分析 series 总量
可以通过指标属于哪个 job
第三步:发现那些指标没有在使用
Grafana Mimirtool 是一个开源的命令行工具, 它可以识别 Mimir、Prometheus 或 Prometheus 的存储中未在Dashboard、Alert 或 recording 中使用的指标。通过 Mimirtool 可以快速发现未使用的指标,并且做出操作
优化监控指标
优化监控指标来解决高基数问题主要从以下维度进行
增加采集间隔
Prometheus 的默认值为 scrape_interval: 15s,或 DPM (Data points Per minute) 4个,但是如果查询语句为 scrape_samples_scraped[1m] 那么可以考虑将这个 job 的 scrape_interval 增加为1m,这样15~60 可以减少近75%的存储成本。
kube-state-metrics:
namespaceOverride: ""
rbac:
create: true
releaseLabel: true
prometheus:
monitor:
enabled: true
## Scrape interval. If not set, the Prometheus default scrape interval is used.
##
interval: ""
优化 histogram
histrogram 是 Prometheus中一种更具有更复杂类型的监控指标,通常用于决定数据的精度,典型的例子就是上面提到的 http_server_requests_seconds_bucket 中的 le ,此时假设 le 代表请求毫秒,那么我们只需要决定你所需要的精度是哪些?例如,如果仅仅需要 1ms, 5ms, 10ms,那么指标 le 标签就控制为3,这样结合 URI 指标,那么这个 histogram 是有限的
# drop all metric series ending with _bucket and where le="0.1xxx"
- source_labels: [__name__, le]
separator: _
regex: ".+_bucket_(0.1+)"
action: "drop"
# Object labels:
__name__: http_server_requests_seconds_bucket
le: 0.114421
这里可以通过 promlabs 来测试你的规则是否是成功的 [2]
删除不需要的标签
对于一些指标,删除了未使用的标签后,反而会使这个指标变得没有意义,并且使这个指标变得序列重复,这个时候可以完整删除这个指标
例如在下面的示例中,第一个示例可以安全地删除 ip 标签,因为其余系列都是唯一的。但在第二个示例中,如果删除 ip 标签将产生重复的时间序列,Prometheus 将删除这些时间序列。my_metric_total在此示例中,Prometheus 将接收具有相同时间戳的值 1、3 和 7,并将丢弃其中的 2 个数据点。
# You can drop ip label, remaining series are still unique
my_metric_total{env=“dev”, ip=“1.1.1.1"} 12
my_metric_total{env=“tst”, ip=“1.1.1.1"} 14
my_metric_total{env=“prd”, ip=“1.1.1.1"} 18
#Remaining values after dropping ip label
my_metric_total{env=“dev”} 12
my_metric_total{env=“tst”} 14
my_metric_total{env=“prd”} 18
# You can not drop ip label, remaining series are not unique
my_metric_total{env=“dev”, ip=“1.1.1.1"} 1
my_metric_total{env=“dev”, ip=“3.3.3.3"} 3
my_metric_total{env=“dev”, ip=“5.5.5.5"} 7
#Remaining values after dropping ip label are not unique
my_metric_total{env=“dev”} 1
my_metric_total{env=“dev”} 3
my_metric_total{env=“dev”} 7
如果无法控制删除标签将导致重复序列,通过 Prometheus sum、avg、min、max等函数可以保留聚合数据,同时删除单个系列。在下面的示例中,我们使用 sum 函数来存储聚合指标,从而允许我们删除单个时间序列。
# sum by env
my_metric_total{env="dev", ip="1.1.1.1"} 1
my_metric_total{env="dev", ip="3.3.3.3"} 3
my_metric_total{env="dev", ip="5.5.5.5"} 7
# Recording rule
sum by(env) (my_metric_total{})
my_metric_total{env="dev"} 11
使用聚合组
例如对于 *_seconds_bucket 类的指标, 通常需要的是一些高纬度的指标,那么这些指标可以通过 recording rules 进行记录和存储
groups:
- interval: 3m
name: kube-apiserver-availability.rules
rules:
- expr: >-
avg_over_time(code_verb:apiserver_request_total:increase1h[30d]) *
24 * 30
record: code_verb:apiserver_request_total:increase30d
- expr: >-
sum by (cluster, code, verb)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"2.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: >-
sum by (cluster, code, verb)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
最后 drop 掉指标
write_relabel_configs:
- source_labels: [__name__]
regex: "apiserver_request_duration_seconds_bucket"
action: drop
recording rules 是允许预先将经常计算的表达式的结果保存为一组新的时间序列的,这种情况下查询的成本会比每次直接查询原始的表达式要快许多,并且在聚合后,可以将原来的指标删掉
Reference
[1] Multi cluster monitoring with Thanos
[2] How to manage high cardinality metrics in Prometheus and Kubernetes
本文发布于Cylon的收藏册,转载请著名原文链接~
链接:https://www.oomkill.com/2023/07/using-thanos-improve-prometheus.md/
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」 许可协议进行许可。